
Reputation: 43217
Is there any logic behind ASCII codes' ordering?
I was teaching C to my younger brother studying engineering. I was explaining him how different data-types are actually stored in the memory. I explained him the logistics behind having signed/unsigned numbers and floating point bit in decimal numbers. While I was telling him about char type in C, I also took him through the ASCII code system and also how char is also stored as 1 byte number.
He asked me why 'A' has been given ASCII code 65 and not anything else? Similarly why 'a' is given the code 97 specifically? Why is there a gap of 6 ASCII codes between the range of capital letters and small letters? I had no idea of this. Can you help me understand this, since this has created a great curiosity to me as well. I've never found any book so far that has discussed this topic.
What is the reason behind this? Are ASCII codes logically organized?
Upvotes: 50
Views: 19683
Answers (7)

Reputation: 6472
This chart shows it quite well from wikipedia: Notice the two columns of control 2 of upper 2 of lower, and then gaps filled in with misc.
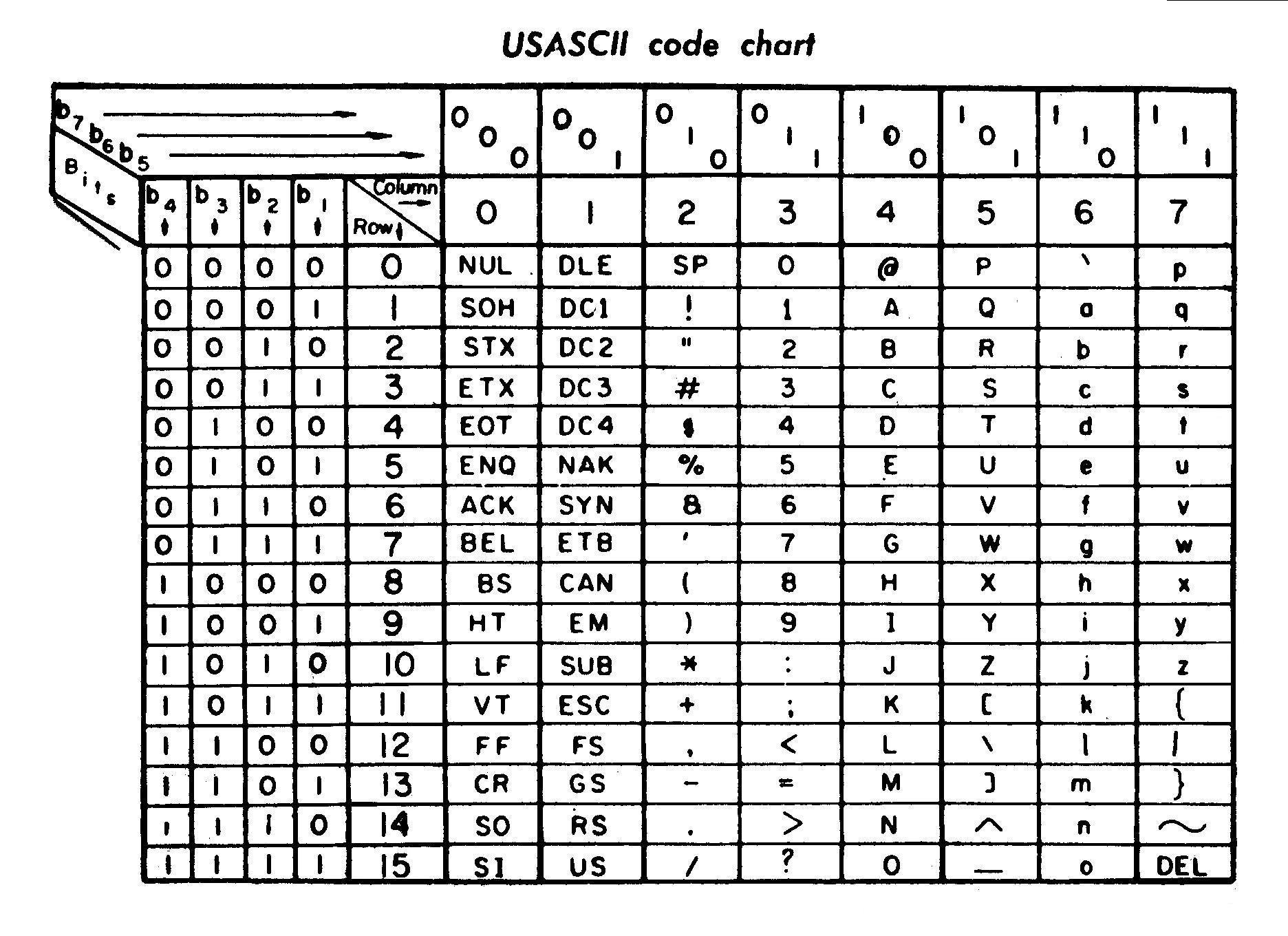
Also bear in mind that ASCII was developed based on what had passed before. For more detail on the history of ASCII, see this superb article by Tom Jennings, which also includes the meaning and usage of some of the stranger control characters.
Upvotes: 13

Reputation: 3223
There are historical reasons, mainly to make ASCII codes easy to convert:
Digits (0x30 to 0x39) have the binary prefix 110000:
0 is 110000
1 is 110001
2 is 110010
etc. So if you wipe out the prefix (the first two '1's), you end up with the digit in binary coded decimal.
Capital letters have the binary prefix 1000000:
A is 1000001
B is 1000010
C is 1000011
etc. Same thing, if you remove the prefix (the first '1'), you end up with alphabet-indexed characters (A is 1, Z is 26, etc).
Lowercase letters have the binary prefix 1100000:
a is 1100001
b is 1100010
c is 1100011
etc. Same as above. So if you add 32 (100000) to a capital letter, you have the lowercase version.
Upvotes: 76

Reputation: 13582
Here is very detailed history and description of ASCII codes: http://en.wikipedia.org/wiki/ASCII
In short:
- ASCII is based on teleprinter encoding standards
- first 30 characters are "nonprintable" - used for text formatting
- then they continue with printable characters, roughly in order they are placed on keyboard. Check your keyboard:
- space,
- upper case sign on number caps: !, ", #, ...,
- numbers
- signs usually placed at the end of keyboard row with numbers - upper case
- capital letters, alphabetically
- signs usually placed at the end of keyboard rows with letters - upper case
- small letters, alphabetically
- signs usually placed at the end of keyboard rows with letters - lower case
Upvotes: 6

Reputation: 4195
The code itself was structured so that most control codes were together, and all graphic codes were together. The first two columns (32 positions) were reserved for control characters.[14] The "space" character had to come before graphics to make sorting algorithms easy, so it became position 0x20.[15] The committee decided it was important to support upper case 64-character alphabets, and chose to structure ASCII so it could easily be reduced to a usable 64-character set of graphic codes.[16] Lower case letters were therefore not interleaved with upper case. To keep options open for lower case letters and other graphics, the special and numeric codes were placed before the letters, and the letter 'A' was placed in position 0x41 to match the draft of the corresponding British standard.[17] The digits 0–9 were placed so they correspond to values in binary prefixed with 011, making conversion with binary-coded decimal straightforward.
Upvotes: 0

Reputation: 91068
- 'A' is 0x41 in hexidecimal.
- 'a' is 0x61 in hexidecimal.
- '0' thru '9' is 0x30 - 0x39 in hexidecimal.
So at least it is easy to remember the numbers for A, a and 0-9. I have no idea about the symbols. See The Wikipedia article on ASCII Ordering.
Upvotes: 0

Reputation: 7317
If you look at the binary representations for 'a' and 'A', you'll see that they only differ by 1 bit, which is pretty useful (turning upper case to lower case or vice-versa is just a matter of flipping a bit). Why start there specifically, I have no idea.
Upvotes: 0

Reputation: 24291
The distance between A and a is 32. That's quite round number, isn't it?
The gap of 6 characters between capital letters and small letters is because (32 - 26) = 6. (Note: there are 26 letters in the English alphabet).
Upvotes: 5
Related Questions
- Description of the algorithm for sorting ASCII characters alphabetically
- Confusion regarding ASCII
- Who determines the ordering of characters
- Relationship between char and ASCII Code?
- Why use ASCII code for letters of the alphabet in if statements, instead of using normal char data type?
- What guarantees does C++ make about the ordering of character literals?
- Information on rationale for unicode codepoint sorting?
- SQL server SORT order does not correspond to ASCII code order
- Order of the characters in character set
- Are ASCII characters always encoded the same way in all character encodings?