
Reputation: 33653
Hash function for short strings
I want to send function names from a weak embedded system to the host computer for debugging purpose. Since the two are connected by RS232, which is short on bandwidth, I don't want to send the function's name literally. There are some 15 chars long function names, and I sometimes want to send those names at a pretty high rate.
The solution I thought about, was to find a hash function which would hash those function names to a single byte, and send this byte only. The host computer would scan all the functions in the source, compute their hash using the same function, and then would translate the hash to the original string.
The hash function must be
- Collision free for short strings.
- Simple (since I don't want too much code in my embedded system).
- Fit a single byte
Obviously, it does not need to be secure by any means, only collision free. So I don't think using cryptography-related hash function is worth their complexity.
An example code:
int myfunc() {
sendToHost(hash("myfunc"));
}
The host would then be able to present me with list of times where the myfunc function was executed.
Is there some known hash function which holds the above conditions?
Edit:
- I assume I will use much less than 256 function-names.
- I can use more than a single byte, two bytes would have me pretty covered.
- I prefer to use a hash function instead of using the same function-to-byte map on the client and the server, because (1) I have no map implementation on the client, and I'm not sure I want to put one for debugging purposes. (2) It requires another tool in my build chain to inject the function-name-table into my embedded system code. Hash is better in this regard, even if that means I'll have a collision once in many while.
Upvotes: 10
Views: 6281
Answers (8)

Reputation: 4518
Described here is a simple way of implementing it yourself: http://www.devcodenote.com/2015/04/collision-free-string-hashing.html
Here is a snippet from the post:
It derives its inspiration from the way binary numbers are decoded and converted to decimal number format. Each binary string representation uniquely maps to a number in the decimal format.
if say we have a character set of capital English letters, then the length of the character set is 26 where A could be represented by the number 0, B by the number 1, C by the number 2 and so on till Z by the number 25. Now, whenever we want to map a string of this character set to a unique number , we perform the same conversion as we did in case of the binary format
Upvotes: 0

Reputation: 44250
If sender and receiver share the same set of function names, they can build identical hashtables from these. You can use the path taken to get to an hash element to communicate this. This can be {starting position+ number of hops} to communicate this. This would take 2 bytes of bandwidth. For a fixed-size table (lineair probing) only the final index is needed to address an entry.
NOTE: when building the two "synchronous" hash tables, the order of insertion is important ;-)
Upvotes: 0

Reputation: 43486
In this case you could just use an enum to identify functions. Declare function IDs in some header file:
typedef enum
{
FUNC_ID_main,
FUNC_ID_myfunc,
FUNC_ID_setled,
FUNC_ID_soundbuzzer
} FUNC_ID_t;
Then in functions:
int myfunc(void)
{
sendFuncIDToHost(FUNC_ID_myfunc);
...
}
Upvotes: 0

Reputation: 700910
No, there isn't.
You can't make a collision free hash code, or even close to it, with just an eight bit hash. If you allow strings that are longer than one character, you have more possible strings than there are possible hash codes.
Why not just extract the function names and give each function name an id? Then you only need a lookup table on each side of the wire.
(As others have shown you can generate a hash algorithm without collisions if you already have all the function names, but then it's easier to just assign a number to each name to make a lookup table...)
Upvotes: 3

Reputation: 12047
If you have a way to track the functions within your code (i.e. a text file generated at run-time) you can just use the memory locations of each function. Not exactly a byte, but smaller than the entire name and guaranteed to be unique. This has the added benefit of low overhead. All you would need to 'decode' the address is the text file that maps addresses to actual names; this could be sent to the remote location or, as I mentioned, stored on the local machine.
Upvotes: 2

Reputation: 121444
You could use a Huffman tree to abbreviate your function names according to the frequency they are used in your program. The most common function could be abbreviated to 1 bit, less common ones to 4-5, very rare functions to 10-15 bits etc. A Huffman tree is not very hard to implement but you will have to do something about the bit alignment.
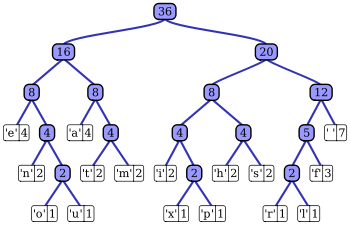
Upvotes: 4

Reputation: 1892
Hmm with only 256 possible values, since you will parse your source code to know all possible functions, maybe the best way to do it would be to attribute a number to each of your function ???
A real hash function would probably won't work because you have only 256 possible hashes. but you want to map at least 26^15 possible values (assuming letter-only, case-insensitive function names). Even if you restricted the number of possible strings (by applying some mandatory formatting) you would be hard pressed to get both meaningful names and a valid hash function.
Upvotes: 4

Reputation: 24180
Minimal perfect hashing guarantees that n keys will map to 0..n-1 with no collisions at all.
C code is included.
Upvotes: 8
Related Questions
- hash function for string
- Creating a faster perfect hash function for 6-byte strings
- Simple hash functions
- How to calculate the hash of a string literal using only the C preprocessor?
- How can I Input variable length string and output user defined length string?
- Very simple cryptography function in C
- Hash function for strings in C
- Hashing function for strings in C
- good hash function
- Constructing a hash table/hash function