
Reputation: 61
Input arff file for Weka Apriori
I am trying to do association mining on version history. I have my transaction data in mysql. Weka apriori algorithm requires arff or csv file in a certain format. It has to have columns for each item. The values will be specified as TRUE or FALSE for each item in a transaction. I am looking for a way to create this file using Weka InstanceQuery. Also what are the options if the transaction data is huge.
Upvotes: 1
Views: 4849
Answers (2)

Reputation: 3520
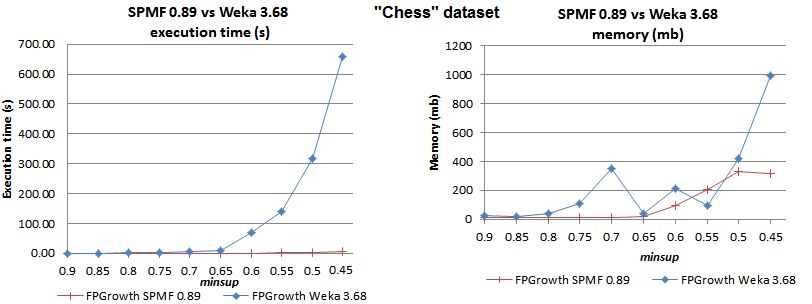
If you want a fast Java implementation of FPGrowth or Apriori, have a look at my project SPMF. The FPGrowth implementation in SPMF beats Weka implementation by up to two orders of magnitude on some datasets. For example, you can see this performance comparison:
http://www.philippe-fournier-viger.com/spmf/performance/chess_fpgrowth_spmf_vs_weka.png
{kind=link}
This is the main project webpage:
http://www.philippe-fournier-viger.com/spmf/index.php
Moreover, note that SPMF offers more than 50 algorithms for itemset mining, association rule mining, sequential pattern mining, etc. Also, the GUI version of SPMF also support the ARFF format used by Weka.
Upvotes: 0

Reputation: 364
I can answer for the second part: options if the transaction data is huge. Weka is a good software but their apriori implementation is horribly slow. I recommend implementations at http://fimi.ua.ac.be/src/ (I used the first one in the list from Ferenc Bodon).
Bodon's implementation use Trie data structure instead of hashtables that Weka uses. Because of this, I found in my work, that Weka would take 3 days to finish something that Bodon's implementation could in less than an hour (yes, the difference is this huge!!).
Plus, Bodon's implementation uses a simple input format: one line for each transaction, with items separated by spaces.
Upvotes: 1
Related Questions
- data file to .arff file for Weka software
- Convert CSV to ARFF using weka
- How do I convert text files to .arff format(weka)
- Creating an arff file for Weka
- Generate an Arff File for Weka
- Reusing Weka Code to Parse ARFF Files
- Convert a Text file in to ARFF Format
- How to convert a text file into ARFF format?
- Telling Weka Which Attributes to Predict in ARFF File?
- classifying data from an ARFF in weka