
Reputation: 1900
Regex an innerHtml of a table to find special charcters
I'm having an hard time to get this..
I have this html code:
<table border='1'><tr><th></th><th>Fact Questions Report Type Count</th></tr><tr>
<td class=' sorting_1'>0 - 18</td><td>78</td></tr><tr><td class=' sorting_1'>19-64</td>
<td>78</td></tr><tr><td class=' sorting_1'>65+</td><td>78</td></tr><tr>
<td class=' sorting_1'>אין גיל</td><td>78</td></tr><tr><td class=' sorting_1'>נפטר</td>
<td>78</td></tr><tr><td class=' sorting_1'>Unknown</td><td>78</td></tr></table>
As you see there are special characters that I want to catch like those:
אין גיל , נפטר
I thought to do a regex that will exclude all words \W and numbers \D and those->=|'
But i can't get it work..
The perfect solution will be getting two items with the special charcters... אין גיל , נפטר
P.S: There could be other special charcters
I will love to see an example for this in here : RegexPal - Online Editor
tnx!
Upvotes: 0
Views: 80
Answers (3)

Reputation: 30283
If you are trying to catch characters in the Hebrew language specifically, you can try
[\u0590-\u05FF\s]+
assuming spaces are okay, or, if using a more advanced regex engine,
[\p{Hebrew}\s]+
If you're actually trying to catch non-English but printable characters then it's hard to help you without seeing what you've tried. \D is a subset of \W, so you should only need \W+, or if I understand you correctly in that you want to exclude ->=|' as well, then [^\w>=|-]+ (the dash must come last here (or in the second position after ^)).
Upvotes: 2

Reputation: 48837
I thought to do a regex that will exclude all words \W and numbers \D and those =|'
Simply do it: [^\w\d=|']+
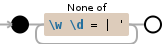
Note that you can't use [^\W]: since \W means anything but \w, [^\W] means anything but anything but \w, i.e. \w (- x - = +).
Upvotes: 1

Reputation: 9291
This one matches only ASCII printable characters:
[\x20-\x7e]
To catch those אין גיל , נפטר (among many other non ASCII characters) you need
[^\x20-\x7e]
As requested: regexpal.com
Upvotes: 1
Related Questions
- Regular expression to parse Table and Select from HTML
- regex to scrape data from html table
- regex find specific tables in html
- Find certain td values from huge table html using regex
- Regex for html tags that are encapsulated by table elements
- How match uniform HTML table?
- Javascript Parse HTML: Get everything inside table tag
- parse HTML table row using regular expression
- Parsing HTML Table using Regex
- What regex would match a nested table with identifiable text in the table cell?