
Reputation: 31
can the same code be used for both hadoop and yarn
I have been thinking about this question for a while now. I have been trying to compare the performance of hadoop 1 vs yarn by running the basic word count example. I am still unsure about how the same .jar file can be used to execute on both the frameworks. As far as I understand yarn has a different set of api's which it uses to set connection with resource manager, create an application master etc. So if I develop an application(.jar), can it be run on both the frameworks without any change in code? Also what could be meaningful parameters to differentiate hadoop vs yarn for a particular application?
Upvotes: 2
Views: 600
Answers (2)
Reputation: 1360
Adding to climbage's answer:

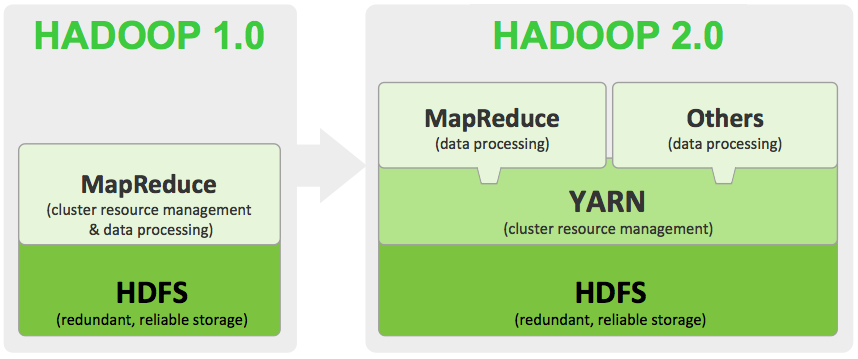
HADOOP Version 1
The JobTracker is responsible for resource management---managing the slave nodes--- major functions involve
- tracking resource consumption/availability
- job life-cycle management---scheduling individual tasks of the job, tracking progress, providing fault tolerance for tasks.
Issues with Hadoop v1 JobTracker is responsible for all spawned MR applications, it is a single point of failure---If JobTracker goes down, all applications in the cluster are killed. Moreover, if the cluster has a large number of applications, JobTracker becomes the performance bottleneck, to address the issues of scalability and job management Hadoop v2 was released.
Hadoop v2
The fundamental idea of YARN is to split the two major responsibilities of the Job-Tracker—that is, resource management and job scheduling/monitoring—into separate daemons: a global ResourceManager and a per-application ApplicationMaster (AM). The ResourceManager and per-node slave, the NodeManager (NM), form the new, and generic, operating system for managing applications in a distributed manner.
To interact with the new resourceManagement and Scheduling, A Hadoop YARN mapReduce Application is developed---MRv2 has nothing to do with the mapReduce programming API
Application programmers will see no difference between MRv1 and MRv2, MRv2 is fully backward compatible---Yes an application(.jar), can be run on both the frameworks without any change in code.
MapReduce was previously integrated in Hadoop Core---the only API to interact with data in HDFS. Now In Hadoop v2 it runs as a separate Application, Hadoop v2 allows other application programming frameworks---e.g MPI---to process HDFS data.
Upvotes: 0

Reputation: 10941
Ok, let's clear up some terms here.
Hadoop is the umbrella system that contains the various components needed for distributed storage and processing. I believe the term you're looking for when you say hadoop 1 is MapReduce v1 (MRv1)
MRv1 is a component of Hadoop that includes the job tracker and task trackers. It only relies on HDFS.
YARN is a component of Hadoop that abstracts out the resource management part of MRv1.
MRv2 is the mapreduce application rewritten to run on top of YARN.
So when you're asking if hadoop 1 is interchangeable with YARN, you're probably actually asking if MRv1 is interchangeable with MRv2. And the answer is generally, yes. The Hadoop system knows how to run the same mapreduce application on both mapreduce platforms.
Upvotes: 2