
Reputation: 1849
How to get specific substring with regex
I'm trying to extract and return the substring from a string which looks like this:
Array ( [query] => Array ( [normalized] => Array ( [0] => Array ( [from] => lion [to] => Lion ) ) [pages] => Array ( [36896] => Array ( [pageid] => 36896 [ns] => 0 [title] => Lion [extract] => The lion (Panthera leo) is one of the four big cats in the genus Panthera and a member of the family Felidae. With some males exceeding 250 kg (550 lb) in weight, it is the second-largest living cat after the tiger. ) ) ) )
The specific substring I need is always located between [extract] => and )))). I'm pretty bad at regex, and would appreciate any help!
I tried
preg_match('/\[extract\] =>(.*?)\)\)\)\)', $c,$hits);
and some other stuff, but nothing worked...
EDIT: Here's the full code I'm using:
$url = 'http://en.wikipedia.org/w/api.php?action=query&prop=extracts&format=txt&exsentences=2&exlimit=10&exintro=&explaintext=&iwurl=&titles=lion';
$ch = curl_init($url);
curl_setopt ($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt ($ch, CURLOPT_USERAGENT, "TestScript"); // required by wikipedia.org server; use YOUR user agent with YOUR contact information. (otherwise your IP might get blocked)
$c = curl_exec($ch);
preg_match('^.*\[extract\].?\=\>.?(.*).?\).?\).?\).?\)$', $c,$hits);
print_r ($hits);
Upvotes: 0
Views: 90
Answers (4)

Reputation: 70732
Well considering that in both of your examples you are missing pattern delimiters, indeed it will not work as expected. Also you need to to match multiple accounts of whitespace to get back your desired result.
preg_match('/\[extract\]\s*=>\s*(.*?)(?:\s*\)){4}/i', $c, $hits);
echo $hits[1];
Output
The lion (Panthera leo) is one of the four big cats in the genus Panthera and a member of the family Felidae. With some males exceeding 250 kg (550 lb) in weight, it is the second-largest living cat after the tiger.
See live demo
Regular expression:

Upvotes: 2

Reputation: 2043
If you really must use regex (and as @JavierDiaz says it seems like overkill) then you could use this:
\[extract\](.*?)\)\s\)\s\)\s\)
Your example appears to have a space between each closing parenthesis at the end of the string - I'm not sure if that's intentional or not. If not, remove the \s bits.
The basic explanation is this:
\[ A literal '['
extract A literal string
\] A literal ']'
( Start of capturing group
.*? Any characters, any number of repetitions but as few as possible (non-greedy)
) End of capturing group
\) A literal ')'
\s Any whitespace
\) A literal ')'
\s Any whitespace
\) A literal ')'
\s Any whitespace
\) A literal ')'
you can try it out using Expresso or any other free RegEx editor (lots of them about).
EDIT: I knocked this up before an edit to the OP's question which adds that the => should not be included. Changing the start to \[extract\].+?\s(.*?) would do the trick, but this has been covered much better by Michael Perrenoud in another answer.
Upvotes: 1

Reputation: 67898
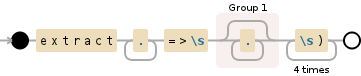
This will do the trick. You're looking for the string extract first, then you want to get to the start of the text with .+=>\s, then you'll grab all the text (.*?) in a non-greedy fashion until you find the end of the string with \s\)\s\)\s\)\s\):
extract.+=>\s(.*?)\s\)\s\)\s\)\s\)

As stated by Javier in Steve's post, you could also do this:
extract.+=>\s(.*?)(?:\s\)){4}
Upvotes: 1

Reputation: 2247
just because it's really funny how you want to solve this, here is regex (edited so there can be whitespace or not between ) ):
^.*\[extract\].?\=\>.?(.*).?\).?\).?\).?\)$
but you should definitelly use array functions to get to [extract] field and you will get it's content which is the part you want
tested here: http://regex101.com/r/qO5vO0
for php:
preg_match('/.*?\[extract\]\s\=\>\s(.*?)\s\)\s\)\s\)\s\)/i', $c, $hits);
echo $hits[1]; //outputs captured string
Upvotes: 1
Related Questions
- Match substring of a substring
- Extracting Sub-String using regex PHP
- Regex to extract substring
- getting desired sub string from string
- How to get this substr with a regex?
- PHP :taking sub strings from given string
- Regular Expression get part of string
- How to get sub string in php
- regular expression to get sub string via php
- i want to build regular expression to extract substring from string in php