
Reputation: 9
Regex exclude value from repetition
I'm working with load files and trying to write a regex that will check for any rows in the file that do not have the correct number of delimiters. Let's pretend the delimiter is % (I'm not sure this text field supports the delimiters that are in the load file). The regex I wrote that finds all rows that are correct is:
^%([^%]*%){20}$
Sometimes it's more beneficial to find any rows that do not have the correct number of delimiters, so to accomplish that, I wrote this:
(^%([^%]*%){0,19}$)|(^%([^%]*%){21,}$)
I'm concerned about the efficiency of this (and any regex I write in general), so I'm wondering if there's a better way to write it, or if the way I wrote it is fine. I thought maybe there would be some way to use alternation with the repetition tokens, such as:
{0,19}|{21,}
but that doesn't seem to work.
If it's helpful to know, I'm just searching through the files in Sublime Text, which I believe uses PCRE. I'm also open to suggestions for making the first regex better in general, although I've found it to work pretty well even in exceptionally large load files.
Upvotes: 0
Views: 146
Answers (1)

Reputation: 12807
If your regex engine supports negative lookaheads, you can slightly modify your original regex.
^(?!%([^%]*%){20}$)
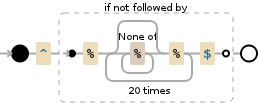
The regex above is useful for test only. If you want to capture, then you need to add .* part.
^(?!%([^%]*%){20}$).*$
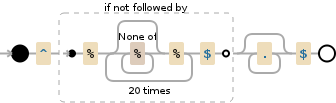
Upvotes: 1
Related Questions
- RegEx: how to don't match a repetition
- Dont match if values repeat in regex
- RegEx for excluding repeating single characters
- How to exclude string using Regex?
- regex exclude for group
- Regex - How can I exclude expressions with duplicated characters
- Regex: Matching a pattern but excluding part of the pattern
- Exclude a pattern in RegEx
- Exclude result from regex
- Regular expression - exclude not needed