
Reputation: 3
Indexing many incoming files
I am trying to write a full text search application which indexes nearly 10000 incoming files every 5 mins. Now before anyone suggests Lucene, Solr, Sphinx, ElasticSearch etc I am not allowed to use either of these. So I am basically trying to read up on building an index. And specifically I am restricted to use MySQL(or any other RDBMS) to store the index(not the file).
Now from what very little I understood about Lucene is that at its core runs an inverted index. I am trying to replicate that by creating a database of word and their corresponding files containing them.(Again I cant use a document which Lucene uses)
I am running a cron job which checks every 5 mins if new files have been uploaded and put them onto a queue. With respect to the queue a Java code runs which creates the index and stores it in the mysql table. All of that FCFS is fine when we are dealing with a few files. But with a load of 10000 files coming in every 5 mins, the indexing will take a lot of time. So is it optimal to spawn a thread every time new files are pushed? That would result in multiple thousand threads running on my server which is already performing other tasks. What would be the best way to handle this task?
Another query I have is: From what I read I understand Lucene uses skip lists to store the list of documents containing words. Something like this: http://4.bp.blogspot.com/-aAvEQEILnEc/USeg8wgdBqI/AAAAAAAAA-s/1D9sNkwVwkk/s1600/p1.png
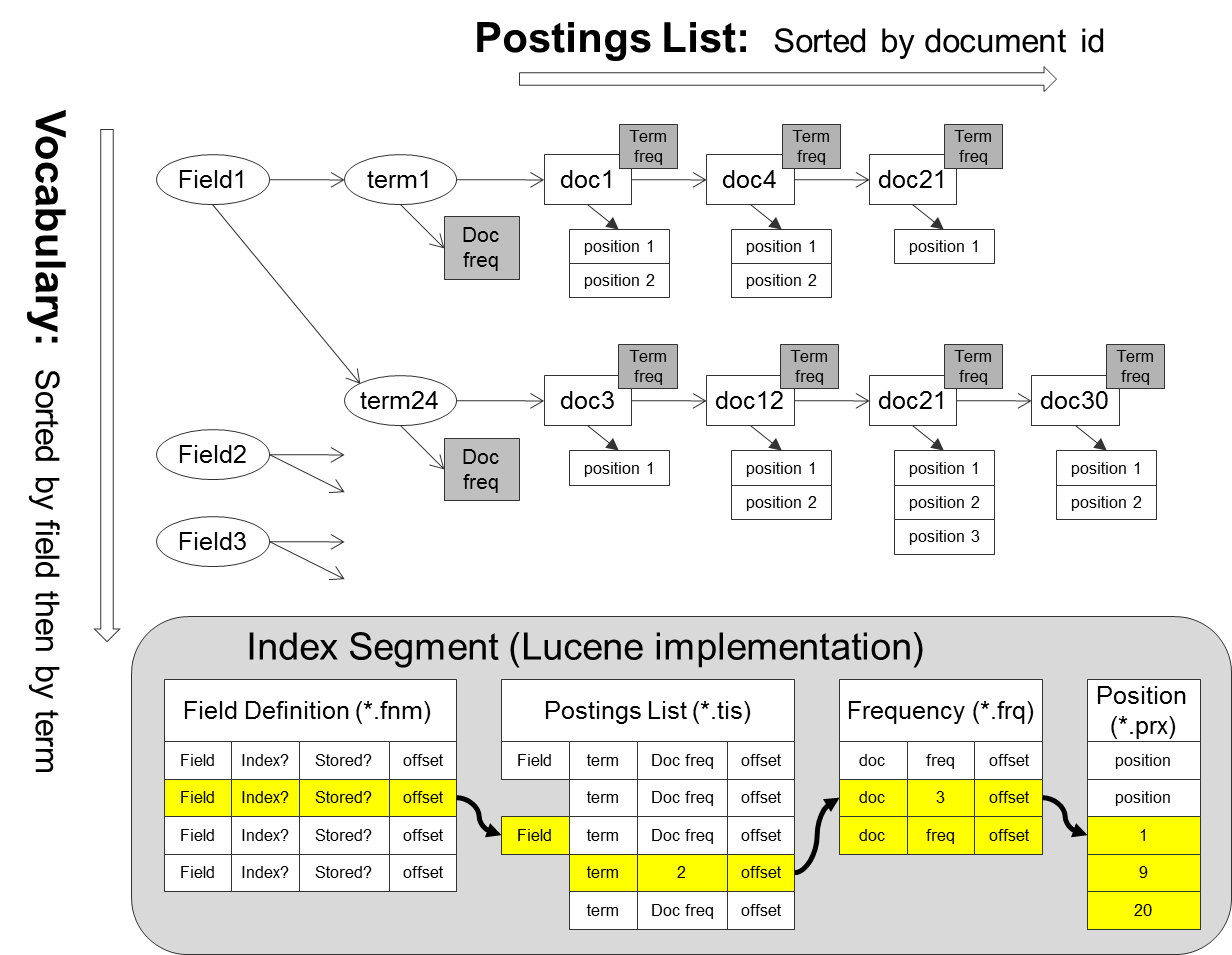{kind=link}
However due to the usage of MySQL I cannot use skip list and instead have to denormalize and face a lot of redundancy. Any way to sort that out?
Upvotes: 0
Views: 53
Answers (1)

Reputation: 108839
You're going to have to load the text of your files into a MySQL table to do this job, then create a FULLTEXT index.
If what you're trying to do is create a scheme by which you can search for text and return the name of the file, you can use these columns.
id (autoincrement)
filepath (path name for the file)
serialno (when whole file is too long for one filetext column, it can be split)
filetext text from the file.
Notice there's a limit on the number of characters in a column that can be indexed with a FULLTEXT index. If you limit the length of the filetext column to 700 characters, you should be fine. That does mean you'll have to split your file text, on word boundaries, into multiple rows in this table, when you load your table.
There is a list of stopwords: words that are not indexed. http://dev.mysql.com/doc/refman/5.5/en/fulltext-stopwords.html
Using FULLTEXT search should work tolerably well for you. As you know, if you want high-capability text search capability, Lucene provides a lot of stuff FULLTEXT doesn't.
Upvotes: 1
Related Questions
- How to index large number of files contained in a single directory using solr?
- Lucene.NET indexing files
- Quick implementation for very large indexed text search?
- Searching contents of files
- Lucene.net with large files
- performing full text searches on huge amount of docs
- Optimizing the number of Lucene index files
- How to go about indexing 300,000 text files for search?
- lucene file index
- How can I index a lot of txt files? (Java/C/C++)