
Reputation: 41
Possible to chain commands using xargs
I'd like to put a sleep between ea of the calls to curl:
ssh someone@somehost "cd /export/home/someone && find . -name '*' -print| xargs -n1 curl -u someone:password ftp://somehost/tmp/ -vT"
Not sure it can be done. Have tried dozens of permutations. Can get a sleep at beginnning/end but not between. Many Thanks
Upvotes: 2
Views: 1170
Answers (5)

Reputation: 33685
If you have GNU Parallel you can run:
ssh someone@somehost "cd /export/home/someone && find . -name '*' -print |
parallel -j1 'sleep 10;curl -u someone:password ftp://somehost/tmp/ -vT'
All new computers have multiple cores, but most programs are serial in nature and will therefore not use the multiple cores. However, many tasks are extremely parallelizeable:
- Run the same program on many files
- Run the same program for every line in a file
- Run the same program for every block in a file
GNU Parallel is a general parallelizer and makes is easy to run jobs in parallel on the same machine or on multiple machines you have ssh access to.
If you have 32 different jobs you want to run on 4 CPUs, a straight forward way to parallelize is to run 8 jobs on each CPU:
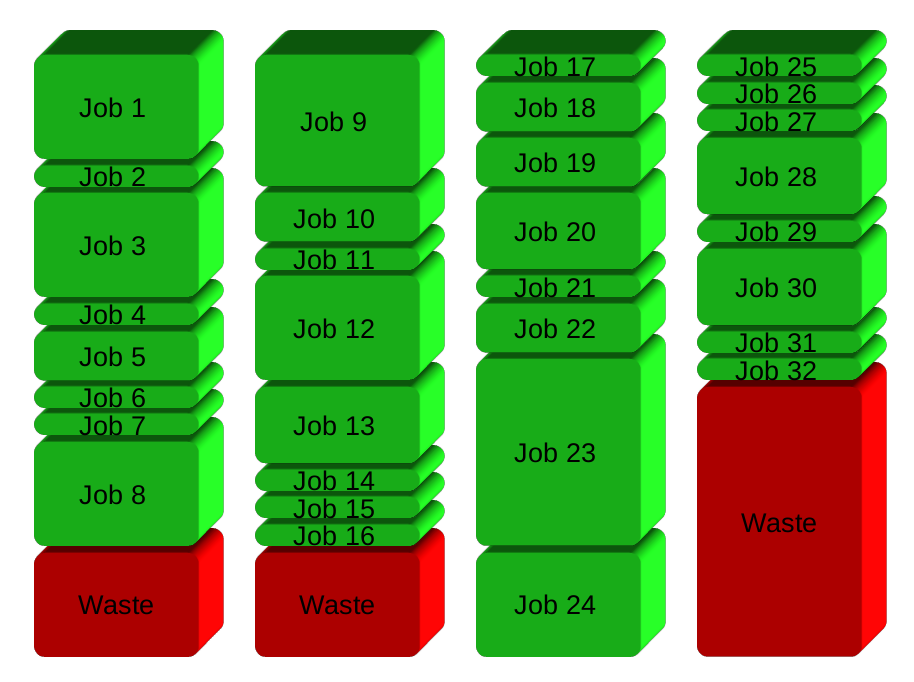
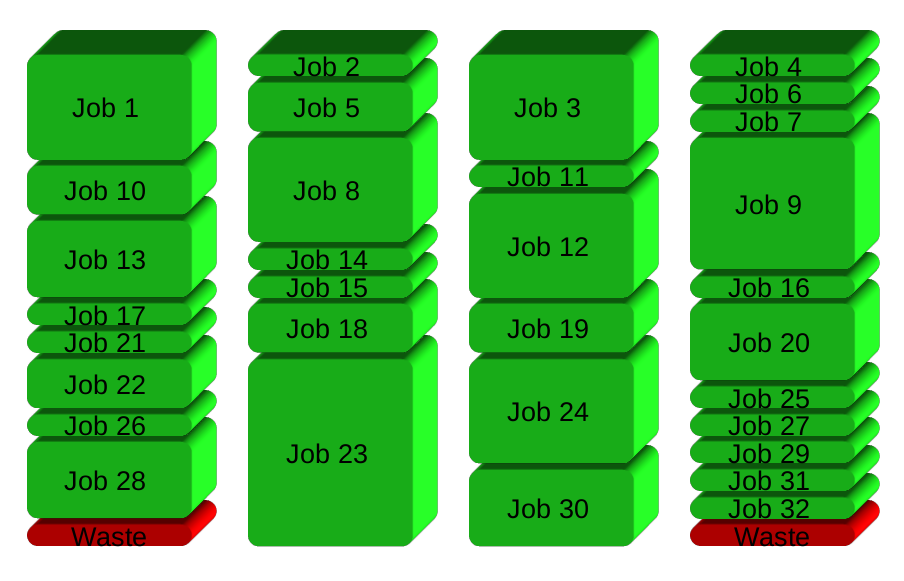
GNU Parallel instead spawns a new process when one finishes - keeping the CPUs active and thus saving time:
Installation
A personal installation does not require root access. It can be done in 10 seconds by doing this:
(wget -O - pi.dk/3 || curl pi.dk/3/ || fetch -o - http://pi.dk/3) | bash
For other installation options see http://git.savannah.gnu.org/cgit/parallel.git/tree/README
Learn more
See more examples: http://www.gnu.org/software/parallel/man.html
Watch the intro videos: https://www.youtube.com/playlist?list=PL284C9FF2488BC6D1
Walk through the tutorial: http://www.gnu.org/software/parallel/parallel_tutorial.html
Sign up for the email list to get support: https://lists.gnu.org/mailman/listinfo/parallel
Upvotes: 0

Reputation: 241701
The interesting part of this question is getting the sleeps between the curls, and not at either the beginning or the end of the sequence of curls.
If you don't have too many files, for some value of "too many" [Note 1]
find . -type f --exec bash -c '
doit() { curl -u someone:password ftp://somehost/tmp/ -vT; }
doit "$1"; for f in "${@:2}"; sleep 2; doit "$f"; done
' _ {} +
I changed the find criteria from -name * (which will match all files and directories) to -type f, which will only match regular files.
The above command line works by using find to invoke (with --exec) an explicit subshell (bash -c) passing it a large number of filenames as arguments ({} +). (The _ is because the first argument to bash -c script is taken as $0, not $1.) The script provided to bash -c just loops through its arguments, using the convenience function doit (which you can easily redefine in case you want to use this idea with a different command.)
It's possible that you didn't really need find because you don't actually care about recursive matching, in which case you could simplify that a bit. Also, with bash 4 you get to use ** for recursive globbing, although ** will match subdirectories as well, so you'd need to filter those out.
Here's a bash 4 example:
doit() { curl -u someone:password ftp://somehost/tmp/ -vT; }
shopt -s globstar
sleep=
for f in **; do if [[ -f $f ]]; then
$sleep
doit "$f"
sleep="sleep 2"
fi done
Notes:
- Unfortunately, the maximum number of files is system dependent, and depends on the amount of memory available for arguments and environment variables (and consequently on the total size of the environment variables). On my system (Ubuntu), the maximum is around 128 kilobytes of filename, which is probably several thousand files unless you use really long filenames. If you exceed this limit, the
bash -cinvocation will be executed more than once, and there will not be a sleep before the second and subsequent invocations, which means that one file in every several thousand will uploaded without a prior sleep. On the other hand, the sleeps along for 2000 files add up to more than an hour, so I don't suppose it is very likely that this restriction applies.
Upvotes: 2

Reputation: 54551
Instead of xargs you could use a subshell:
ssh someone@somehost 'cd /export/home/someone && find . -name "*" -print| (while read file; do curl -u someone:password ftp://somehost/tmp/ -vT "$file"; sleep 10; done)'
Note that I also flipped your single and double quotes so that the local shell doesn't try to interpret $file.
Upvotes: 0

Reputation: 80931
xargs accepts a single command. You need to get that single command to do two things.
Try
| xargs -n1 bash -c 'curl ... "$0"; sleep ##'
or (to use the "normal" positional arguments you need to fill in $0 manually).
| xargs -n1 bash -c 'curl ... "$1"; sleep 1' -
Upvotes: 3

Reputation: 1823
You can use a loop in that.
ssh someone@somehost "for i in `ls`; do curl -u someone:password ftp://somehost/tmp/ -vT ; sleep 10;done"
Upvotes: -1
Related Questions
- Running multiple commands with xargs
- Pipe commands at each xargs pass
- How to use xargs to run command multiple times?
- how to pipe multi commands to bash?
- Using xargs to run multiple commands
- How to combine multiple commands when piped through xargs?
- xargs with multiple commands
- Can xargs execute a subshell command for each argument?
- Xargs: running 3 separate xargs commands in parallel
- Command composition in bash