
Reputation: 32412
How do you match only valid roman numerals with a regular expression?
Thinking about my other problem, i decided I can't even create a regular expression that will match roman numerals (let alone a context-free grammar that will generate them)
The problem is matching only valid roman numerals. Eg, 990 is NOT "XM", it's "CMXC"
My problem in making the regex for this is that in order to allow or not allow certain characters, I need to look back. Let's take thousands and hundreds, for example.
I can allow M{0,2}C?M (to allow for 900, 1000, 1900, 2000, 2900 and 3000). However, If the match is on CM, I can't allow following characters to be C or D (because I'm already at 900).
How can I express this in a regex?
If it's simply not expressible in a regex, is it expressible in a context-free grammar?
Upvotes: 198
Views: 111178
Answers (18)

Reputation: 872
I could assume that my test strings started and ended with roman numerals like chapter numbers or so and use a simple
^[LXVI]{1,8}$
to find the ones under 100. Extend it by [MDCLXVI]{1,12} for greater numerals.
Prefix with ^CHAPTER , ^SECTION , etc to include them.
Upvotes: 0

Reputation: 882606
You can use the following regex for this:
^M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$
Breaking it down, M{0,4} specifies the thousands section and basically restrains it to between 0 and 4000. It's a relatively simple:
0: <empty> matched by M{0}
1000: M matched by M{1}
2000: MM matched by M{2}
3000: MMM matched by M{3}
4000: MMMM matched by M{4}
You could, of course, use something like M* to allow any number (including zero) of thousands, if you want to allow bigger numbers.
Next is (CM|CD|D?C{0,3}), slightly more complex, this is for the hundreds section and covers all the possibilities:
0: <empty> matched by D?C{0} (with D not there)
100: C matched by D?C{1} (with D not there)
200: CC matched by D?C{2} (with D not there)
300: CCC matched by D?C{3} (with D not there)
400: CD matched by CD
500: D matched by D?C{0} (with D there)
600: DC matched by D?C{1} (with D there)
700: DCC matched by D?C{2} (with D there)
800: DCCC matched by D?C{3} (with D there)
900: CM matched by CM
Thirdly, (XC|XL|L?X{0,3}) follows the same rules as previous section but for the tens place:
0: <empty> matched by L?X{0} (with L not there)
10: X matched by L?X{1} (with L not there)
20: XX matched by L?X{2} (with L not there)
30: XXX matched by L?X{3} (with L not there)
40: XL matched by XL
50: L matched by L?X{0} (with L there)
60: LX matched by L?X{1} (with L there)
70: LXX matched by L?X{2} (with L there)
80: LXXX matched by L?X{3} (with L there)
90: XC matched by XC
And, finally, (IX|IV|V?I{0,3}) is the units section, handling 0 through 9 and also similar to the previous two sections (Roman numerals, despite their seeming weirdness, follow some logical rules once you figure out what they are):
0: <empty> matched by V?I{0} (with V not there)
1: I matched by V?I{1} (with V not there)
2: II matched by V?I{2} (with V not there)
3: III matched by V?I{3} (with V not there)
4: IV matched by IV
5: V matched by V?I{0} (with V there)
6: VI matched by V?I{1} (with V there)
7: VII matched by V?I{2} (with V there)
8: VIII matched by V?I{3} (with V there)
9: IX matched by IX
Just keep in mind that that regex will also match an empty string. If you don't want this (and your regex engine is modern enough), you can use positive look-ahead:
^(?=.)M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$
This is a "check to match but discard" operation, meaning it looks ahead to check that the first character exists (.) after the start marker (^) but doesn't absorb that first character. For example, if the string was M, that would match the . but still be available for the next section of the regex, M{0,4}. However, the empty string would not match the look-ahead so would fail.
Another alternative, if you are not restricted to just a regex, would be to check that the length is not zero beforehand.
Upvotes: 385

Reputation: 2915
hope this one is correct - it requires the most basic flavor of ERE only ...
...as long as you don't mind it also matching the empty string, i.e. str == ""
/^M*(D?C(CC?)?|C?[DM])?(L?X(XX?)?|X?[LC])?(V?I(II?)?|I?[VX])?$/
Upvotes: 0

Reputation: 28974
Some really amazing answers here but none fit the bill for me since I needed to be able to match only valid Roman numerals within a string without matching empty strings and only match numerals that are on their own (i.e. not within a word).
Let me present you to Reilly's Modern roman numerals strict expression:
^(?=[MDCLXVI])M*(C[MD]|D?C{0,3})(X[CL]|L?X{0,3})(I[XV]|V?I{0,3})$
Out of the box it was pretty close to what I needed but it will only match standalone Roman numerals and when changed to match in string it will match empty strings at certain points (where a word begins with an uppercase V, M etc.) and will also give partial matches of invalid Roman numerals such as MMLLVVDD, XXLLVVDD, MMMMDLVX, XVXDLMM and MMMCCMLXXV.
So, after a bit of modification I and ended up with this:
(?<![MDCLXVI])(?=[MDCLXVI])M{0,3}(?:C[MD]|D?C{0,3})(?:X[CL]|L?X{0,3})(?:I[XV]|V?I{0,3})[^ ]\b
The added negative lookbehind will ensure that it doesn't do partial matches of invalid Roman numerals and locking down the first M to 3 since that is the highest it goes in the Roman numeral standard form.
As of right now, this is the only regular expression that passes my extensive test suit of over 4000 tests that includes all possible Roman numerals from 1-3999, Roman numerals within strings and invalid Roman numerals like the ones I mentioned above.
Here's a screenshot of it in action from https://regex101.com/:

Upvotes: 3

Reputation: 93
The positive look-behind and look-ahead suggested by @paxdiablo in order to avoid matching empty strings seems not working to me.
I have fixed it by using negative look-ahead instead :
(?!$)M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})
NB: if you append something (eg. "foobar" at the end of the regex, then obviously you'll have to replace (?!$) by (?!f) (where f is the first character of "foobar").
Upvotes: 1

Reputation: 1158
The following expression worked for me to validate the roman number.
^M{0,4}(C[MD]|D?C{0,3})(X[CL]|L?X{0,3})(I[XV]|V?I{0,3})$
Here,
M{0,4}will match thousandsC[MD]|D?C{0,3}will match HundredsX[CL]|L?X{0,3}will match TensI[XV]|V?I{0,3}will match Units
Below is a visualization that helps to understand what it is doing, preceded by two online demos:
Python Code:
import re
regex = re.compile("^M{0,4}(C[MD]|D?C{0,3})(X[CL]|L?X{0,3})(I[XV]|V?I{0,3})$")
matchArray = regex.match("MMMCMXCIX")
Upvotes: 1

Reputation: 1
This works in Java and PCRE regex engines and should now work in the latest JavaScript but may not work in all contexts.
(?<![A-Z])(M*(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3}))(?![A-Z])
The first part is the atrocious negative lookbehind. But, for logical purposes it is the easiest to understand. Basically, the first (?<!) is saying don't match the middle ([MATCH]) if there are letters coming before the middle ([MATCH]) and the last (?!) is saying don't match the middle ([MATCH]) if there are letters coming after it.
The middle ([MATCH]) is just the most commonly used regex for matching the sequence of Roman Numerals. But now, you don't want to match that if there are any letters around it.
See for yourself. https://regexr.com/4vce5
Upvotes: 0

Reputation: 4264
I've seen multiple answers that doesn't cover empty strings or uses lookaheads to solve this. And I want to add a new answer that does cover empty strings and doesn't use lookahead. The regex is the following one:
^(I[VX]|VI{0,3}|I{1,3})|((X[LC]|LX{0,3}|X{1,3})(I[VX]|V?I{0,3}))|((C[DM]|DC{0,3}|C{1,3})(X[LC]|L?X{0,3})(I[VX]|V?I{0,3}))|(M+(C[DM]|D?C{0,3})(X[LC]|L?X{0,3})(I[VX]|V?I{0,3}))$
I'm allowing for infinite M, with M+ but of course someone could change to M{1,4} to allow only 1 or 4 if desired.
Below is a visualization that helps to understand what it is doing, preceded by two online demos:
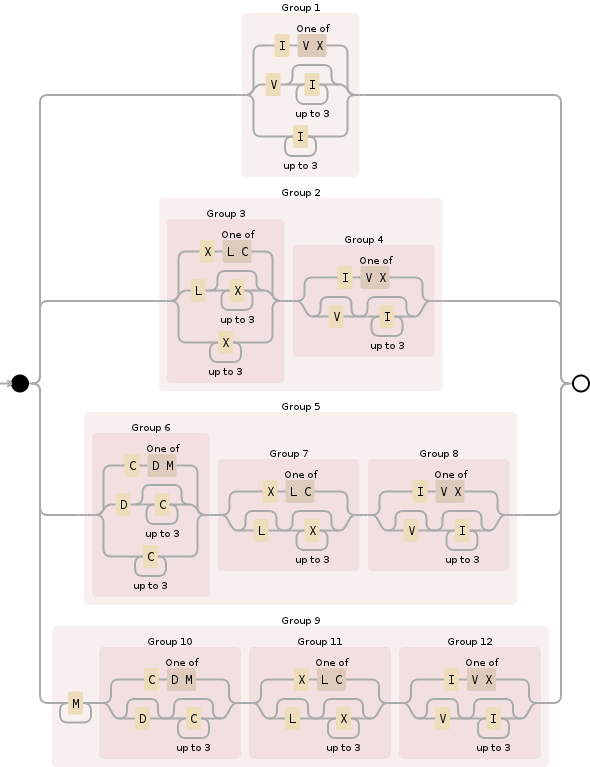
Upvotes: 2
Reputation:
Im answering this question Regular Expression in Python for Roman Numerals here
because it was marked as an exact duplicate of this question.
It might be similar in name, but this is a specific regex question / problem
as can be seen by this answer to that question.
The items being sought can be combined into a single alternation and then
encased inside a capture group that will be put into a list with the findall()
function.
It is done like this :
>>> import re
>>> target = (
... r"this should pass v" + "\n"
... r"this is a test iii" + "\n"
... )
>>>
>>> re.findall( r"(?m)\s(i{1,3}v*|v)$", target )
['v', 'iii']
The regex modifications to factor and capture just the numerals are this :
(?m)
\s
( # (1 start)
i{1,3}
v*
| v
) # (1 end)
$
Upvotes: 1

Reputation: 61
In my case, I was trying to find and replace all occurences of roman numbers by one word inside the text, so I couldn't use the start and end of lines. So the @paxdiablo solution found many zero-length matches. I ended up with the following expression:
(?=\b[MCDXLVI]{1,6}\b)M{0,4}(?:CM|CD|D?C{0,3})(?:XC|XL|L?X{0,3})(?:IX|IV|V?I{0,3})
My final Python code was like this:
import re
text = "RULES OF LIFE: I. STAY CURIOUS; II. NEVER STOP LEARNING"
text = re.sub(r'(?=\b[MCDXLVI]{1,6}\b)M{0,4}(?:CM|CD|D?C{0,3})(?:XC|XL|L?X{0,3})(?:IX|IV|V?I{0,3})', 'ROMAN', text)
print(text)
Output:
RULES OF LIFE: ROMAN. STAY CURIOUS; ROMAN. NEVER STOP LEARNING
Upvotes: 4

Reputation: 1596
Just to save it here:
(^(?=[MDCLXVI])M*(C[MD]|D?C{0,3})(X[CL]|L?X{0,3})(I[XV]|V?I{0,3})$)
Matches all the Roman numerals. Doesn't care about empty strings (requires at least one Roman numeral letter). Should work in PCRE, Perl, Python and Ruby.
Online Ruby demo: http://rubular.com/r/KLPR1zq3Hj
Online Conversion: http://www.onlineconversion.com/roman_numerals_advanced.htm
Upvotes: 20

Reputation: 65
I would write functions to my work for me. Here are two roman numeral functions in PowerShell.
function ConvertFrom-RomanNumeral
{
<#
.SYNOPSIS
Converts a Roman numeral to a number.
.DESCRIPTION
Converts a Roman numeral - in the range of I..MMMCMXCIX - to a number.
.EXAMPLE
ConvertFrom-RomanNumeral -Numeral MMXIV
.EXAMPLE
"MMXIV" | ConvertFrom-RomanNumeral
#>
[CmdletBinding()]
[OutputType([int])]
Param
(
[Parameter(Mandatory=$true,
HelpMessage="Enter a roman numeral in the range I..MMMCMXCIX",
ValueFromPipeline=$true,
Position=0)]
[ValidatePattern("^M{0,3}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$")]
[string]
$Numeral
)
Begin
{
$RomanToDecimal = [ordered]@{
M = 1000
CM = 900
D = 500
CD = 400
C = 100
XC = 90
L = 50
X = 10
IX = 9
V = 5
IV = 4
I = 1
}
}
Process
{
$roman = $Numeral + " "
$value = 0
do
{
foreach ($key in $RomanToDecimal.Keys)
{
if ($key.Length -eq 1)
{
if ($key -match $roman.Substring(0,1))
{
$value += $RomanToDecimal.$key
$roman = $roman.Substring(1)
break
}
}
else
{
if ($key -match $roman.Substring(0,2))
{
$value += $RomanToDecimal.$key
$roman = $roman.Substring(2)
break
}
}
}
}
until ($roman -eq " ")
$value
}
End
{
}
}
function ConvertTo-RomanNumeral
{
<#
.SYNOPSIS
Converts a number to a Roman numeral.
.DESCRIPTION
Converts a number - in the range of 1 to 3,999 - to a Roman numeral.
.EXAMPLE
ConvertTo-RomanNumeral -Number (Get-Date).Year
.EXAMPLE
(Get-Date).Year | ConvertTo-RomanNumeral
#>
[CmdletBinding()]
[OutputType([string])]
Param
(
[Parameter(Mandatory=$true,
HelpMessage="Enter an integer in the range 1 to 3,999",
ValueFromPipeline=$true,
Position=0)]
[ValidateRange(1,3999)]
[int]
$Number
)
Begin
{
$DecimalToRoman = @{
Ones = "","I","II","III","IV","V","VI","VII","VIII","IX";
Tens = "","X","XX","XXX","XL","L","LX","LXX","LXXX","XC";
Hundreds = "","C","CC","CCC","CD","D","DC","DCC","DCCC","CM";
Thousands = "","M","MM","MMM"
}
$column = @{Thousands = 0; Hundreds = 1; Tens = 2; Ones = 3}
}
Process
{
[int[]]$digits = $Number.ToString().PadLeft(4,"0").ToCharArray() |
ForEach-Object { [Char]::GetNumericValue($_) }
$RomanNumeral = ""
$RomanNumeral += $DecimalToRoman.Thousands[$digits[$column.Thousands]]
$RomanNumeral += $DecimalToRoman.Hundreds[$digits[$column.Hundreds]]
$RomanNumeral += $DecimalToRoman.Tens[$digits[$column.Tens]]
$RomanNumeral += $DecimalToRoman.Ones[$digits[$column.Ones]]
$RomanNumeral
}
End
{
}
}
Upvotes: -2

Reputation: 222929
import re
pattern = '^M{0,3}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$'
if re.search(pattern, 'XCCMCI'):
print 'Valid Roman'
else:
print 'Not valid Roman'
For people who really want to understand the logic, please take a look at a step by step explanation on 3 pages on diveintopython.
The only difference from original solution (which had M{0,4}) is because I found that 'MMMM' is not a valid Roman numeral (also old Romans most probably have not thought about that huge number and will disagree with me). If you are one of disagreing old Romans, please forgive me and use {0,4} version.
Upvotes: 7

Reputation: 86473
Steven Levithan uses this regex in his post which validates roman numerals prior to "deromanizing" the value:
/^M*(?:D?C{0,3}|C[MD])(?:L?X{0,3}|X[CL])(?:V?I{0,3}|I[XV])$/
Upvotes: 0

Reputation: 2467
To avoid matching the empty string you'll need to repeat the pattern four times and replace each 0 with a 1 in turn, and account for V, L and D:
(M{1,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})|M{0,4}(CM|C?D|D?C{1,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})|M{0,4}(CM|CD|D?C{0,3})(XC|X?L|L?X{1,3})(IX|IV|V?I{0,3})|M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|I?V|V?I{1,3}))
In this case (because this pattern uses ^ and $) you would be better off checking for empty lines first and don't bother matching them. If you are using word boundaries then you don't have a problem because there's no such thing as an empty word. (At least regex doesn't define one; don't start philosophising, I'm being pragmatic here!)
In my own particular (real world) case I needed match numerals at word endings and I found no other way around it. I needed to scrub off the footnote numbers from my plain text document, where text such as "the Red Seacl and the Great Barrier Reefcli" had been converted to the Red Seacl and the Great Barrier Reefcli. But I still had problems with valid words like Tahiti and fantastic are scrubbed into Tahit and fantasti.
Upvotes: 13

Reputation: 1040
The problem of the solution from Jeremy and Pax is, that it does also match "nothing".
The following regex expects at least one roman numeral:
^(M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})|[IDCXMLV])$
Upvotes: -1

Reputation: 755026
Fortunately, the range of numbers is limited to 1..3999 or thereabouts. Therefore, you can build up the regex piece-meal.
<opt-thousands-part><opt-hundreds-part><opt-tens-part><opt-units-part>
Each of those parts will deal with the vagaries of Roman notation. For example, using Perl notation:
<opt-hundreds-part> = m/(CM|DC{0,3}|CD|C{1,3})?/;
Repeat and assemble.
Added: The <opt-hundreds-part> can be compressed further:
<opt-hundreds-part> = m/(C[MD]|D?C{0,3})/;
Since the 'D?C{0,3}' clause can match nothing, there's no need for the question mark. And, most likely, the parentheses should be the non-capturing type - in Perl:
<opt-hundreds-part> = m/(?:C[MD]|D?C{0,3})/;
Of course, it should all be case-insensitive, too.
You can also extend this to deal with the options mentioned by James Curran (to allow XM or IM for 990 or 999, and CCCC for 400, etc).
<opt-hundreds-part> = m/(?:[IXC][MD]|D?C{0,4})/;
Upvotes: 8

Reputation: 103575
Actually, your premise is flawed. 990 IS "XM", as well as "CMXC".
The Romans were far less concerned about the "rules" than your third grade teacher. As long as it added up, it was OK. Hence "IIII" was just as good as "IV" for 4. And "IIM" was completely cool for 998.
(If you have trouble dealing with that... Remember English spellings were not formalized until the 1700s. Until then, as long as the reader could figure it out, it was good enough).
Upvotes: 30
Related Questions
- roman numerals and regex
- Regex matching certain number of characters + regex with roman numerals
- python regex(VALIDATING ROMAN NUMBERS)
- Regex Match Roman Numerals from 0-39 Only
- Match roman numbers using regex
- Match only roman numerals with regular expression
- Regex to match numbers written as words, digits or roman numerals
- Single Regex for filtering roman numerals from the text files
- How to create regular expression checking Roman numerals?
- Matching Roman Numbers