
Reputation: 6419
Retrieve digits after specific string in R
I have a bunch of strings that contain the word "radius" followed by one or two digits. They also contain a lot of other letters, digits, and underscores. For example, one is "inflow100_radius6_distance12". I want a regex that will just return the one or two digits following "radius." If R recognized \K, then I would just use this:
radius\K[0-9]{1,2}
and be done. But R doesn't allow \K, so I ended up with this instead (which selects radius and the following numbers, and then cuts off "radius"):
result <- regmatches(input_string, gregexpr("radius[0-9]{1,2}", input_string))
result <- unlist(substr(result, 7, 8)))
I'm pretty new to regex, so I'm sure there's a better way. Any ideas?
Upvotes: 5
Views: 797
Answers (2)

Reputation: 70750
\K is recognized. You can solve the problem by turning on the perl = TRUE parameter.
result <- regmatches(x, gregexpr('radius\\K\\d+', x, perl=T))
Upvotes: 8

Reputation: 270378
1) Match the entire string replacing it with the digits after radius:
sub(".*radius(\\d+).*", "\\1", "inflow100_radius6_distance12")
## [1] "6"
The regular expression can be visualized as follows:
.*radius(\d+).*

2) This also works, involves a simpler regular expression and converts it to numeric at the same time:
library(gsubfn)
strapply("inflow100_radius6_distance12", "radius(\\d+)", as.numeric, simplify = TRUE)
## [1] 6
Here is a visualization of the regular expression:
radius(\d+)
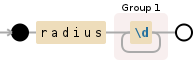
Upvotes: 4
Related Questions
- Extracting number after a specific phrase
- How to extract a specific instance of a string of digits after a specific character using regex
- Extract digits after matching the certain string second time
- extract number after specific string
- how to extract the first digits from a string with sub in r
- r - separate digits from string
- Regular expression to get a number after particular string in R
- R: How to extract specific digits from a string?
- R regex extract number after/before string
- Regular expression to capture the digits