
Reputation: 51
Trying to match this regex
I have been trying to match this regex to no avail. What i need to do is do a non greedy match which will match the latest number to a specific word in this case: Next:
Here is the text:
<a href="/forum/view-forum/standard-trading-shops/page/1">Prev</a>
<a href="/forum/view-forum/standard-trading-shops/page/1">1</a>
<a class="current" href="/forum/view-forum/standard-trading-shops/page/2">2</a>
<a href="/forum/view-forum/standard-trading-shops/page/3">3</a>
<a href="/forum/view-forum/standard-trading-shops/page/4">4</a>
<span class="separator">...</span><a href="/forum/view-forum/standard-trading-shops/page/3029">3029</a>
<a href="/forum/view-forum/standard-trading-shops/page/3030">3030</a>
<a href="/forum/view-forum/standard-trading-shops/page/3">Next</a>
I need to find 3030 as my answer which in extend is the highest number from the passage.
What i tired to do:
(/d)+.*?Next
This however always matches (1) the first number on the 2nd line instead of the highest number 3030. It was my understanding that .*? does a non greedy match which should match the latest occurrence.
Can anyone help me? thanks M
Upvotes: 1
Views: 61
Answers (3)

Reputation: 43447
Using BeautifulSoup is the preferred method for parsing HTML.
s = """<a href="/forum/view-forum/standard-trading-shops/page/1">Prev</a>
<a href="/forum/view-forum/standard-trading-shops/page/1">1</a>
<a class="current" href="/forum/view-forum/standard-trading-shops/page/2">2</a>
<a href="/forum/view-forum/standard-trading-shops/page/3">3</a>
<a href="/forum/view-forum/standard-trading-shops/page/4">4</a>
<span class="separator">...</span><a href="/forum/view-forum/standard-trading-shops/page/3029">3029</a>
<a href="/forum/view-forum/standard-trading-shops/page/3030">3030</a>
<a href="/forum/view-forum/standard-trading-shops/page/3">Next</a>"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(s)
text = soup.text.splitlines()
index = text.index('Next')
result = text[index-1]
>>> print result
3030
Not as elegant as a regular expression, but it's the proper way to do it.
Upvotes: 0

Reputation: 4659
Parsing HTML with regexes is generally ill-advised. This website explains why and gives you better alternatives in all major languages.
You haven't specified which language you're working in, but this regex will work in most cases:
(\d+)(?:<[^>]+>[^<]*){2}Next
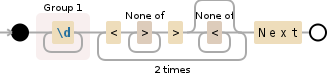
The number will be in the first capture-group. Effectively I'm saying that after the number should be {2} instances of of < then any characters that aren't > until the > and optionally some characters that aren't < until the next instance. After those 2 instances of <something> should be the word Next.
Upvotes: 0

Reputation: 67968
^[\s\S]*>(\d+)<
You can try this.Grab the group 1 or capture 1.See demo.
https://regex101.com/r/sJ9gM7/28
Here you do a greedy match upto a number.So this will stop at the last occurance of number between ><.. will not match newlines by default so either DOTALL or [\s\S] can be used.
Upvotes: 1
Related Questions
- How to match this expression with regex?
- Trying to find matching regular expression
- Regex pattern to match this pattern
- How do I match this regex
- Regular expression to match this simple pattern
- A RegEx to Match This
- How do I match this string
- Can't Figure Out Specific RegEx
- How can I make this regex match correctly?
- need help with regex