
Reputation: 402
Prevent URL skipping when Bulk extracting with import.io
So, I've been extracting lot of data with import.io desktop app for quite some time; but what always bugged me is when you try to bulk extract multiple URLs it always skips around half of them.
It's not URL problem, if you take same let's say 15 URLs it will return for example first time 8, second time 7, third time 9; some links will be extracted first time but will be skipped second time and so on.
I am wondering is there a way to make it process all URL I feed it?
Upvotes: 2
Views: 228
Answers (1)

Reputation: 323
I have encountered this issue a few times when I am extracting data. This typically is due to the speed of the Bulk Extract requesting URLs from the site's servers.
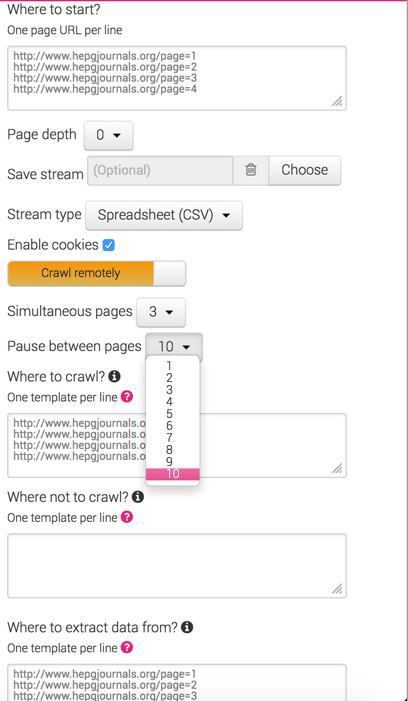
A workaround is to use a Crawler like an Extractor. You can paste the URLs that you created/collected into the Where to Start, Where to Crawl, and Where to Get Data From sections (you need to click on the advanced settings button in the Crawler).
Make sure to turn on 0 depth Crawl. (This turns the Crawler into an Extractor; i.e. no discovery of additional URLs)
Increase the Pause Between Pages.
Here is screenshot of one I built sometime ago. http://i.gyazo.com/92de3b7c7fbca2bc4830c27aefd7cba4.png
{kind=link}
Upvotes: 1
Related Questions
- How to scrape multiple pages with Import.io
- Trying to Import Data from Several URLs but Always Stuck on the First URL
- How to import python file from multiple urls
- Url regex from data extracted from <script>
- Listing extractors from import.io
- URL Redirection in import.io
- Import.io bulk extract slows down when more URLs are in list
- Collect the url of scraped page
- Xpath to url for import.io
- How can I extract data from multiple webpage using one import.io connector?