Reputation: 3386
Extract unquoted text from a string
I have a string that may contain random segments of quoted and unquoted texts. For example,
s = "\"java jobs in delhi\" it software \"pune\" hello".
I want to separate out the quoted and unquoted parts of this string in python.
So, basically I expect the output to be:
quoted_string = "\"java jobs in delhi\"" "\"pune\""
unquoted_string = "it software hello"
I believe using a regex is the best way to do it. But I am not very good with regex. Is there some regex expression that can help me with this? Or is there a better solution available?
Upvotes: 2
Views: 1168
Answers (4)

Reputation: 3420
If your quotes are as basic as in your example, you could just split; example:
for s in (
'"java jobs in delhi" it software "pune" hello',
'foo "bar"',
):
result = s.split('"')
print 'text between quotes: %s' % (result[1::2],)
print 'text outside quotes: %s' % (result[::2],)
Otherwise you could try:
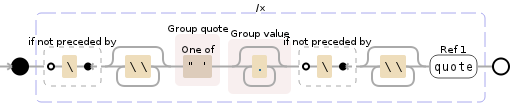
import re
pattern = re.compile(
r'(?<!\\)(?:\\\\)*(?P<quote>["\'])(?P<value>.*?)(?<!\\)(?:\\\\)*(?P=quote)'
)
for s in data:
print pattern.findall(s)
I explain the regex (I use it in ihih):
(?<!\\)(?:\\\\)* # find backslash
(?P<quote>["\']) # any quote character (either " or ')
# which is *not* escaped (by a backslash)
(?P<value>.*?) # text between the quotes
(?<!\\)(?:\\\\)*(?P=quote) # end (matching) quote
Upvotes: 3

Reputation: 15537
You should use Python's shlex module, it's very nice:
>>> from shlex import shlex
>>> def get_quoted_unquoted(s):
... lexer = shlex(s)
... items = list(iter(lexer.get_token, ''))
... return ([i for i in items if i[0] in "\"'"],
[i for i in items if i[0] not in "\"'"])
...
>>> get_quoted_unquoted("\"java jobs in delhi\" it software \"pune\" hello")
(['"java jobs in delhi"', '"pune"'], ['it', 'software', 'hello'])
>>> get_quoted_unquoted("hello 'world' \"foo 'bar' baz\" hi")
(["'world'", '"foo \'bar\' baz"'], ['hello', 'hi'])
>>> get_quoted_unquoted("does 'nested \"quotes\" work' yes")
(['\'nested "quotes" work\''], ['does', 'yes'])
>>> get_quoted_unquoted("what's up with single quotes?")
([], ["what's", 'up', 'with', 'single', 'quotes', '?'])
>>> get_quoted_unquoted("what's up when there's two single quotes")
([], ["what's", 'up', 'when', "there's", 'two', 'single', 'quotes'])
I think this solution is as simple as any other solution (basically a oneliner, if you remove the function declaration and grouping) and it handles nested quotes well etc.
Upvotes: 1

Reputation: 96016
Use a regex for that:
re.findall(r'"(.*?)"', s)
will return
['java jobs in delhi', 'pune']
Upvotes: 1

Reputation: 3343
I dislike regex for something like this, why not just use a split like this?
s = "\"java jobs in delhi\" it software \"pune\" hello"
print s.split("\"")[0::2] # Unquoted
print s.split("\"")[1::2] # Quoted
Upvotes: 3
Related Questions
- Extract text between quotation using regex python
- Extract a string between double quotes
- Extract string within matching quotes
- Extracting substrings between single quotes
- Python - Extract text from string
- Extract string from regex
- Retrieve text between quotes, including escaped quotes
- Extract text from Regular Expression?
- Extracting string between quotes split across multiple lines in Python
- extract string within string with out double quote