
Reputation: 71
Parallel and distributed algorithms for matrix multiplication
The problem comes when I looked up Wikipedia page of Matrix multiplication algorithm
It says:
This algorithm has a critical path length of
Θ((log n)^2)steps, meaning it takes that much time on an ideal machine with an infinite number of processors; therefore, it has a maximum possible speedup ofΘ(n3/((log n)^2))on any real computer.
(The quote is from section "Parallel and distributed algorithms/Shared-memory parallelism.")
Since assuming there are infinite processors, the operation of multiplication should be done in O(1). And then just add all elements up, and this should be a constant time as well. Therefore, the longest critical path should be O(1) instead of Θ((log n)^2).
I was wondering if there is difference between O and Θ and where am I mistaken?
The problem has been solved, big thanks to @Chris Beck. The answer should be separated into two parts.
First, a low mistake is I do not count the time of summation. The summation takes O(log(N)) in operation( think about binary adding ).
Second, as Chris points out, the non-trivial problems takes time O(log(N)) in the processor. Above all, the longest critical path should be O(log(N)^2) instead of O(1).
For confusion of O and Θ, I found the answer in Big_O_Notation_Wikipedia.
Big O is the most commonly used asymptotic notation for comparing functions, although in many cases Big O may be replaced with Big Theta Θ for asymptotically tighter bounds.
I was wrong for the last conclusion. The O(log(N)^2) does not happen at summation and processor, but happen at when we split the matrix. Thanks @displayName for reminding me of this. In addition, Chris' answer for non trivial problem is still very useful for researching parallel system. Thank all warm heart answerers below!
Upvotes: 5
Views: 2867
Answers (3)

Reputation: 14389
There are two aspects to this question, addressing which the question will be completely answered.
- Why can't we bring the run-time to O(1) by throwing in sufficient number of processors?
- How is the critical path length for Matrix Multiplication equal to Θ(log2n)?
Going after the questions one by one.
Infinite number of processors
The simple answer to this point is in understanding two terms viz. Task Granularity and Task Dependency.
- Task Granularity - implies how fine the task decomposition is. Even if you have infinite processors, the maximum decomposition is still finite for a problem.
- Task Dependency - implies that what are the steps that simply can be performed sequentially only. Like, you cannot modify the input unless you have read it. So modifying will always be preceded by reading of the input and cannot be done in parallel with it.
So, for a process that has four steps A, B, C, D such that D is dependent on C, C is dependent on B and B is dependent on A, then a single processor will work as fast as 2 processors, will work as fast as 4 processors, will work as fast as infinite processors.
This explains the first bullet.
Critical Path Length for Parallel Matrix Multiplication
- If you had to divide a square matrix of size
n X ninto four blocks of size[n/2] X [n/2]each and then continue dividing until you reach down to a single element (or matrix of size1 X 1) the number of levels this tree-like design would have is O(log (n)). - Thus, for matrix multiplication in parallel, since we have to recursively divide not one but two matrices of size n, down to their last element, it takes O(log2n) time.
- In fact, this bound is tighter and is not just O(log2n), but Θ(log2n).
The difference between Big O and Theta is that Big O only tells that a process won't go above what's mentioned by Big O, while Theta tells that function is not just having an upper bound, but also the lower bound with what's mentioned in Theta. Hence, effectively, the plot of the complexity of the function would be sandwiched between the same function, multiplied with two different constants as depicted in the image below, or in other words, the function will grow at the same rate:

Image taken from: http://xlinux.nist.gov/dads/Images/thetaGraph.gif
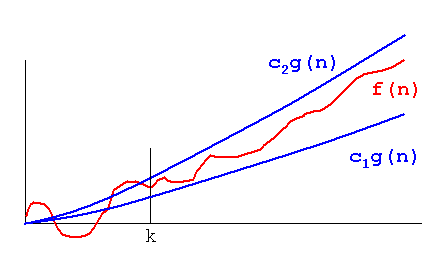{kind=link}
So, I'd say that for your case, you can ignore the notation and you are not "gravely" mistaken between the two.
To conclude...
I'd like to define another term called Speedup or Parallelism. It is defined as the ratio of best sequential execution time (also called work) and parallel execution time. The best sequential access time, already given on the wikipedia page you've linked to is O(n3). The parallel execution time is O(log2n).
Hence, the speedup is = O(n3/log2n).
And even though the speedup looks so simple and straightforward, achieving it in actual cases is very difficult due to the communication costs that are inherent in moving data.
Upvotes: 4

Reputation: 1257
Matrix multiplication can be done in O(logn) using n^3 processors. Here is how:
Input: two N x N matrices M1 and M2. M3 will store the result.
Assign N processors to compute the value of M3[i][j]. M3[i][j] is defined as Sum(M1[i][k] * M2[k][j]), k = 1..N. In the first step all processors do a single multiplication. First one does M1[i][1] * M2[1][j], second one does M1[i][2] * M2[2][j], ... . Each processor keeps its value. Now we have to sum all these multiplied pairs. We can do this in O(logn) time if we organize the summation into a tree:
4 Stage 3
/ \
2 2 Stage 2
/ \ / \
1 1 1 1 Stage 1
We run this algorithm in parallel for all (i, j) using N^3 processors.
Upvotes: 1

Reputation: 16204
"Infinite number of processors" is perhaps a poor way of phrasing it.
When people study parallel computation from a theoretical viewpoint, they basically want to ask "assuming I have more processors than I need, how fast can I possibly do it".
It's a well-defined question -- just because you have a huge number of processors doesn't mean matrix multiplication is O(1).
Suppose you take any naive algorithm for matrix multiplication on a single processor. Then I tell you, you can have one processor for every single assembly instruction if you like, so the program can be "parallelized" in that each processor performs only a single instruction and then shares its result with the next.
The time of that computation is not "1" cycle, because some of the processors have to wait for other processors to finish, and those processors are waiting on different processors, etc.
Generally speaking, nontrivial problems (problems in which none of the input bits are irrelevant) require time O(log n) in parallel computation, otherwise the "answer" processor at the very end doesn't even have time to depend on all of the input bits.
Problems for which O(log n) parallel time is tight, are said to be highly parallelizable. It is widely conjectured that some of them don't have this property. If that's not true, then in terms of computational complexity theory, P would collapse to a lower class which it is conjectured not to.
Upvotes: 1
Related Questions
- Java parallel matrix multiplication
- The openmp matrix multiplication
- Speeding up matrix multiplication using SIMD and openMP
- Parallelized Matrix Multiplication
- How to do matrix multiplication efficiently
- Parallel Matrix Multiplication using multi GPU
- parallelizing matrix multiplication through threading and SIMD
- algorithm for matrix matrix multiplication of size o(100)
- Parallel Matrix Multiplication in Java 6
- Parallel Matrix Multiplication in MATLAB