Reputation:
Scrape a price off a website
I'm trying to scrape a price from a web page using PHP and Regexes. The price will be in the format £123.12 or $123.12 (i.e., pounds or dollars).
I'm loading up the contents using libcurl. The output of which is then going into preg_match_all. So it looks a bit like this:
$contents = curl_exec($curl);
preg_match_all('/(?:\$|£)[0-9]+(?:\.[0-9]{2})?/', $contents, $matches);
So far so simple. The problem is, PHP isn't matching anything at all - even when there are prices on the page. I've narrowed it down to there being a problem with the '£' character - PHP doesn't seem to like it.
I think this might be a charset issue. But whatever I do, I can't seem to get PHP to match it! Anyone have any ideas?
(Edit: I should note if I try using the Regex Test Tool using the same regex and page content, it works fine)
Upvotes: 0
Views: 1538
Answers (3)

Reputation: 140953
Have you try to use \ in front of £
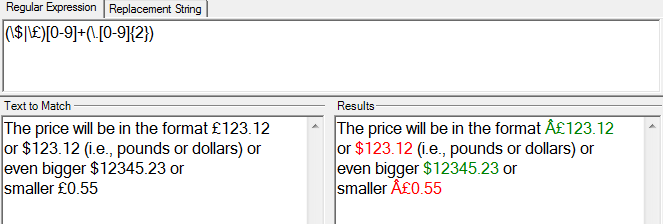
preg_match_all('/(\$|\£)[0-9]+(\.[0-9]{2})/', $contents, $matches);
I have try this expression with .Net with \£ and it works. I just edited it and removed some ":".

(source: clip2net.com)
{kind=link}
Read my comment about the possibility of Curl giving you bad encoding (comment of this post).
Upvotes: 1

Reputation: 10033
This should work for simple values.
'#(?:\$|\£|\€)(\d+(?:\.\d+)?)#'
This will not work with thousand separator like 234,343 and 34,454.45.
Upvotes: 0

Reputation: 49354
maybe pound has it's html entity replacement? i think you should try your regexp with some sort of couching program (i.e. match it against fixed text locally).
i'd change my regexp like this: '/(?:\$|£)\d+(?:\.\d{2})?/'
Upvotes: 0
Related Questions
- Parse HTML and create an associative array of products and their prices
- Get all currency/price expressions from a block of text
- Regex scrape the price without any tags
- regular expression to find price
- Scraping a page to retrieve prices, currency code messing things up
- web scraping to extract dollar price
- RegEx - How to Extract Price?
- Regex does not work while parsing price
- Extracting a price using preg_match in PHP
- Regex to match a price string