Reputation:
Match a not 8 character (digit/a-z/A-Z) long word through regex
This is the first question I post so sorry for anything I might screw up.
I've spent the past hour experimenting and searching for a way to replace "not 8 character (digit/a-z/A-Z) long word" with blank space (or in other words delete anything but those words) in Notepad++ through regular expressions.
I managed to bookmark the lines containing them but I'm stuck with the whole line that has that word, I just want those specific words. I'd appreciate any help, thanks a lot!
Edit2: A better way to phrase this is:
To remove anything that isn't: 8 character long that starts with an S and only contains digits and letters. In other words, remove anything that isn't S******* where *=digit,letter
Edit: I realized that's not enough to understand the situation so here's an example. I want to process this:
Here's your first code: S284JF2B
Here's your second code: SKE093JF
Here's your third code: S28fka30
And get this output:
S284JF2B
SD34EQ5M
SASFKA30
The actual file has lots of other characters that are not just digits/letters and the codes I want on the output are always 8 character long (digits/Uppercase letters) always starting with an S.
Upvotes: 1
Views: 2700
Answers (5)

Reputation: 91508
I'd use the following regex ^.*(S[A-Z0-9]{7})(?!=[A-Z0-9]).*$:
- Ctrl+H
- Find what:
^.*(S[A-Z0-9]{7})(?!=[A-Z0-9]).*$ - Replace with:
$1 - DO NOT check
. matches newline - Replace all
Explanation:
^ : begining of line
.* : any character 0 or more times
( : start group 1
S[A-Z0-9]{7}: S followed by 7 alphanumeric characters
) : end group
(?!=[A-Z0-9]) : negative lookahead to make sure there are no alphanum after
.* : any character 0 or more times
$ : end of line
Upvotes: 0

Reputation: 12950
I have tried with following text to match your problem with the additional non-alphanumeric characters.
<protocol="toto" john="doe" Here's your first code: S284JF2B sign="+" />
<protocol="toto" john="doe" Here's your second code: SKE093JF sign="+" />
<protocol="toto" john="doe" 8char="s2345678" Here's your third code: S28fka30 sign="+" />
I used the following regular expression
\b(\w{1,7}|(?=[^S])\w{8}|S(?![A-Za-z0-9]{8})\w{8}|\w{9,})\b|[^\w\r\n]
I obtained only the codes when replacing with nothing and selected the option "Match case" in the replacement windows.
With a live demo here: https://regex101.com/r/wW3eB1
Explanations:
\b(...)\b: word between boundaries\w{1,7}: word of 1 to 7 letters(?=[^S])\w{8}: word of 8 letters not starting by 'S'S(?![A-Za-z0-9]{8})\w{8}: word starting with a 'S', with 8 characters but containing something other than alpha-numeric (i.e. an underscore)|\w{9,}: word of 9 letters or more[^\w\r\n]: character that is neither a word or an EOL character
Upvotes: 0

Reputation: 15010
I have two possible solutions. Both solutions require the string to be 8 characters long and begin with an S.
Given the this sample text:
the problem is it's not the words that do not contain any words that I don't want
but actually any string that isn't a string that starts with an S and is 8 character long.
Example: S294KS12 this is the type of string I want on the document. Contains 8 characters
that are either digits or letters and starts with an S
SOMETIME
S294KS12
S1234567
S123456A
Option 1
This solution only finds strings which are 8 characters long and start with an S.
\bS[A-Z0-9]{7}\b
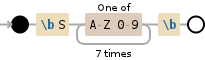
Live Demo
https://regex101.com/r/lK0aO9/1
Matches from Sample
S294KS12
SOMETIME
S294KS12
S1234567
S123456A
Explanation
NODE EXPLANATION
----------------------------------------------------------------------
\b the boundary between a word char (\w) and
something that is not a word char
----------------------------------------------------------------------
S 'S'
----------------------------------------------------------------------
[A-Z0-9]{7} any character of: 'A' to 'Z', '0' to '9'
(7 times)
----------------------------------------------------------------------
\b the boundary between a word char (\w) and
something that is not a word char
----------------------------------------------------------------------
Options 2
This solution does additional checking to ensure there is at least one additional letter and one number.
\bS(?=[A-Z]*[0-9])(?=[0-9]*[A-Z])[A-Z0-9]{7}\b

Live Demo
https://regex101.com/r/vH4lX2/3
Matches from Sample
S294KS12
S294KS12
S123456A
Explanation
NODE EXPLANATION
----------------------------------------------------------------------
\b the boundary between a word char (\w) and
something that is not a word char
----------------------------------------------------------------------
S 'S'
----------------------------------------------------------------------
(?= look ahead to see if there is:
----------------------------------------------------------------------
[A-Z]* any character of: 'A' to 'Z' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
[0-9] any character of: '0' to '9'
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
(?= look ahead to see if there is:
----------------------------------------------------------------------
[0-9]* any character of: '0' to '9' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
[A-Z] any character of: 'A' to 'Z'
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
[A-Z0-9]{7} any character of: 'A' to 'Z', '0' to '9'
(7 times)
----------------------------------------------------------------------
\b the boundary between a word char (\w) and
something that is not a word char
----------------------------------------------------------------------
Putting all together
To replace everything else, then I'd incoprporate the regular expression into ( ... )\s?|. Which will match everything, including the desired strings.
If you then use $1 in the Replace with option in Notepad++, then you'll be left with just your desired strings.
I recommend using option 2 above, and inserting that into the expression so it looks like this:
(\bS(?=[A-Z]*[0-9])(?=[0-9]*[A-Z])[A-Z0-9]{7}\b)\s?|.
Replace with: $1
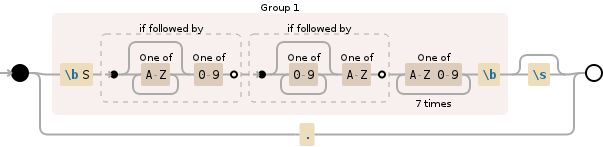
Live Demo
https://regex101.com/r/gO7zV7/1
Upvotes: 2

Reputation: 20238
To match everything but the tokens from your example:
(^|\s)(?!S\w{7}\b)\S*
For a live demo, see https://regex101.com/r/rW8mF0/4
To match any non-8 character word:
\b\w{1,7}\b|\b\w{9,}\b

It matches words of length 1 - 7 OR words of length 9 and more.
For a live demo, see https://regex101.com/r/fX2sE5/1
Upvotes: 1
Reputation: 15010
Description
Lacking any proper examples, this will find substrings that are 8 characters long and not containing any letters. The substring must be bracketed by either whitespace or at the beginning or end of the string
(?<=\s|^)[^a-zA-Z0-9\s]{8}(?=\s|$)
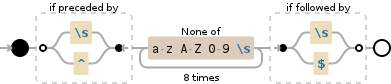
Example
Live Demo
https://regex101.com/r/gS9uN7/1
Sample text
I've spent the past hour experimenting and searching for a way to replace "not 8 character (digit/a-z/A-Z) $#@!#$>< fd long word" with blank space (or in other words delete anything but those words) in Notepad++ through regular expressions.
Sample Matches
$#@!#$><
After Replacement
I've spent the past hour experimenting and searching for a way to replace "not 8 character (digit/a-z/A-Z) fd long word" with blank space (or in other words delete anything but those words) in Notepad++ through regular expressions.
Explanation
NODE EXPLANATION
----------------------------------------------------------------------
(?<= look behind to see if there is:
----------------------------------------------------------------------
\s whitespace (\n, \r, \t, \f, and " ")
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
^ after an optional start of the string
----------------------------------------------------------------------
) end of look-behind
----------------------------------------------------------------------
[^a-zA-Z0-9\s]{8} any character except: 'a' to 'z', 'A' to
'Z', '0' to '9', whitespace (\n, \r, \t, \f, and " ")
(8 times)
----------------------------------------------------------------------
(?= look ahead to see if there is:
----------------------------------------------------------------------
\s whitespace (\n, \r, \t, \f, and " ")
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
$ before an optional \n, and the end of a
"line"
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
Upvotes: 1
Related Questions
- RegEx match open tags except XHTML self-contained tags
- Regex: matching up to the first occurrence of a character
- Regex to match only letters
- Regular expression to match a line that doesn't contain a word
- Regex Match all characters between two strings
- Regex: match everything but a specific pattern
- How to match "any character" in regular expression?
- What regex will match every character except comma ',' or semi-colon ';'?