
Reputation: 9645
Finding the optimal combination of algorithms in an sklearn machine learning toolchain
In sklearn it is possible to create a pipeline to optimize the complete tool chain of a machine learning setup, as shown in the following sample:
from sklearn.pipeline import Pipeline
from sklearn.svm import SVC
from sklearn.decomposition import PCA
estimators = [('reduce_dim', PCA()), ('svm', SVC())]
clf = Pipeline(estimators)
Now a pipeline represents by definition a serial process. But what if I want to compare different algorithms on the same level of a pipeline? Say I want to try another feature transformation algorithm additionally to PCA and another machine learning algorithm such as trees additionally to SVM, and get the best of the 4 possible combinations? Can this be represented by some kind of parallel pipe or is there a meta algorithm for this in sklearn?
Upvotes: 1
Views: 551
Answers (2)
Reputation: 397
The pipeline is not a parallel process. It's rather sequential (Pipeline) - see here the documentation, mentionning :
Sequentially apply a list of transforms and a final estimator. [...] The purpose of the pipeline is to assemble several steps that can be cross-validated together while setting different parameters.
Thus, you should create two pipelines by just changing one parameters. Then, you would be able to compare the results and keep the better. If you want to, let's say, compare more estimators, you can automize the process
Here is a simple example :
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_regression
from sklearn.decomposition import PCA
clf1 = SVC(Kernel = 'rbf')
clf2 = RandomForestClassifier()
feat_selec1 = SelectKBest(f_regression)
feat_selec2 = PCA()
for selec in [('SelectKBest', feat_selec1), ('PCA', feat_select2)]:
for clf in [('SVC', clf1), ('RandomForest', clf2):
pipe = Pipeline([selec, clf])
//Do your training / testing cross_validation
Upvotes: 2

Reputation: 136665
A pipeline is something sequential:
Data -> Process input with algorithm A -> Process input with algorithm B -> ...
Something parallel, and I also think what you're looking for is called an "Ensemble". For example, in a classification context you can train several SVMs but on different features:
|-SVM A gets features x_1, ... x_n -> vote for class 1 -|
DATA -|-SVM B gets features x_{n+1}, ..., x_m -> vote for class 1 -| -> Classify
|-SVM C gets features x_{m+1}, ..., x_p -> vote for class 0 -|
In this small example 2 of 3 classifiers voted for class 1, the 3rd voted for class 0. So by majority vote, the ensemble classifies the data as class 1. (Here, the classifiers are executed in parallel)
Of course, you can have several pipelines in an ensemble.
See sklearns Ensemble methods for a pretty good summary.
A short image summary I made a while ago for different ensemble methods:
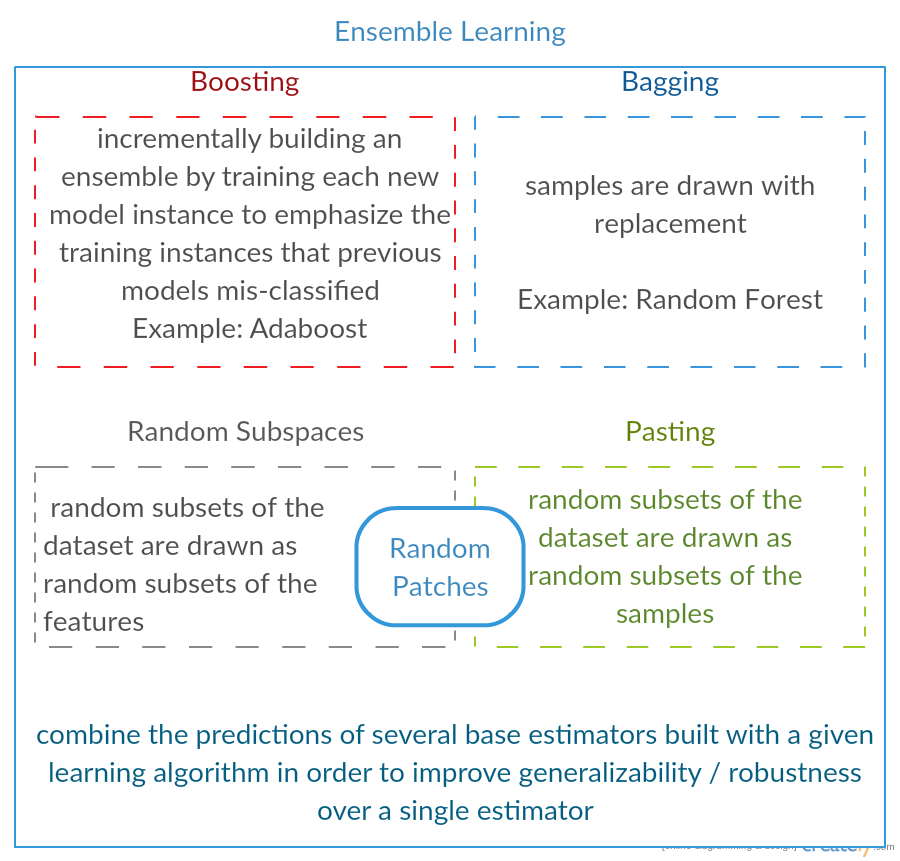
Upvotes: 1
Related Questions
- Compare multiple algorithms with sklearn pipeline
- Ensemble learning Python-Random Forest, SVM, KNN
- Automatically selecting the best of several estimators in scikit-learn
- Best way to combine probabilistic classifiers in scikit-learn
- Ensembling the 10-fold models
- machine learning from sklearn
- Python - machine learning
- Sklearn list of algorithms
- Supervised machine learning with scikit-learn
- how can I combine training set specific learned parameters with sklearn online (out-of-core) learning