
Reputation: 1611
Better approach for updating multiple data
I have this MySQL table, where row contact_id is unique for each user_id.
history:
- hist_id: int(11) auto_increment primary key
- user_id: int(11)
- contact_id: int(11)
- name: varchar(50)
- phone: varchar(30)
From time to time, server will receive a new list of contacts for a specific user_id and need to update this table, inserting, deleting or updating data that is different from previous information.
For example, currenty data is:

So, server receive this data:

And the new data is:

As you can see, first row (John) was updated, second row (Mary) was deleted and some other row (Jeniffer) was included.
Today what I am doing is deleting all rows with a specific user_id, and inserting the new data. But the autoincrement field (hist_id) is getting bigger and bigger...
Obs: Table have about 80 thousand records, and this update will occur 30 times a day or more.
I have some (related) questions:
1. In this scenario, do you think deleting all records from a specific user_id and inserting updated data is a good approach?
2. What about removing the autoincrement field? I don't need it, but I think it is not a good idea to have a table without a primary key.
3. Or maybe the better approach is to loop new data, selecting each user_id / contact_id for comparing values to update?
PS. For better approach I mean the most efficient way
Thank you so much for any help!
Upvotes: 4
Views: 366
Answers (1)

Reputation: 487
- In this scenario, do you think deleting all records from a specific user_id and inserting updated data is a good approach?
Short Answer No. You should be taking advantage of 'upsert' which is short for 'insert on duplicate key update'. What this means is that if they key pair you're inserting already exists, update the specified columns with the specified data. You then shorten your logic and reduce increments. Here's an example, using your table structure that should work. This is also assuming that you have set the user_id and contact_id fields to unique.
INSERT INTO history (user_id, contact_id, name, phone)
VALUES
(1, 23, 'James Jr.', '(619)-543-6222')
ON DUPLICATE KEY UPDATE
name=VALUES(name),
phone=VALUES(phone);
This query should retain the contact_id but overwrite the prexisting data with the new data.
- What about removing the autoincrement field? I don't need it, but I think it is not a good idea to have a table without a primary key.
Primary keys do not imply auto incremented values. I could have a varchar field as the primary key containing names of fruits and vegetables. Is this optimized for performance? Probably not. There many situations that might call for auto increment and there are definite reasons to avoid it. It all depends on how you wish to access the data and how this can impact future expansion. In your situation, I would start over on the table structure and re-think how you wish to store and access the data. Do you want to write more logic to control the data OR do you want the data to flow naturally by itself? You've made a history table that is functioning more like a hybrid many-to-one crosswalk at first glance. Without looking at the remaining table structure, I can't necessarily say on a whim that it's not a good idea. What I can say is that I would do this a bit differently. I will answer this more specifically in the next question.
- Or maybe the better approach is to loop new data, selecting each user_id / contact_id for comparing values to update?
I would avoid looping through the data in order to update it. That is a job for SQL and it does this job well. Sometimes, we might find ourselves in a situation where we must do this to either extract data in a specific format or to repair data in some way however, avoid doing this for inserting or updating the data. It can negatively impact performance and you will likely paint yourself into a corner.
Back to what I said toward the end of your second question which will help you see what I am talking about. I am going to assume that user_id is a primary key that is auto-incremented in your user table. I will do some guestimation here and show you an example of how you can redesign your user, contact and phone number structure. The following is a quick model I threw together that shows the foreign key relationship between the tables.
Note: The column names and overall data arrangement could be done differently but I did this quickly to give you a decent example of a normalized database structure. All of the foreign keys have a structural layout which separates your data in a way that enables you to control the flow of data as it enters and leaves your system. Here's the screenshot of the database model I threw together using MySQL Workbench.

(source: xonos.net)
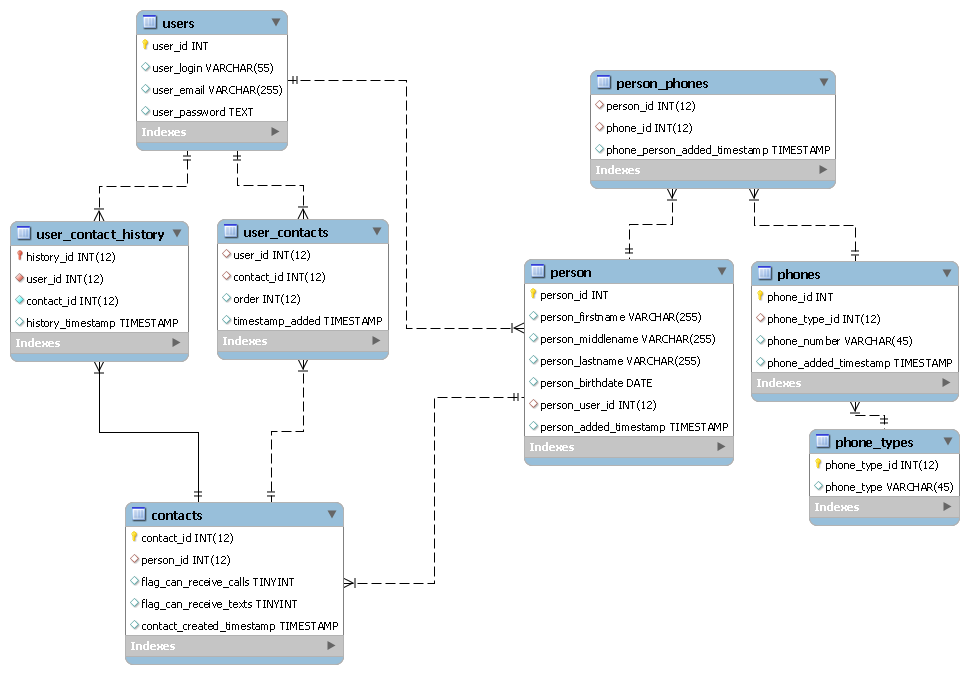{kind=link}
Here's the SQL so that you can look at it more closely.
You'll notice that the "person" table is extracted from users but shares data with contacts. This enables you to store all "people" in one place, all "users" in another and all "contacts" in another. Now, why would we do this? The number one reason can be explained in two scenarios.
1.) Say we have someone, in this example I'll call him "Jim Bean". "Jim Bean" works for the company, so he is a user of the system. But, "Jim Bean" happens to own a side business and does contact work for the company at the same time. So, he is both a contact and a user of the system. In a more "flat table" environment, we would have two records for Jim Bean that contain the same data which could become outdated or incorrect, quickly.
2.) Let's say that Jim did some bad things and the company wants nothing to do with him anymore. They don't want any record of him - as if he never existed. All that we have to do is delete Jim Bean from the Person table. That's it. Since the foreign relationship has "CASCADE" on update/delete - this automatically propagate and clears out the other tables related to him.
I highly recommend that you do some reading on normalized data structure. It has saved me many hours once I got the hang of it and I will never go back.
Upvotes: 2
Related Questions
- How do I update multiple data using single query?
- Update MySQL with multiple data
- Updating multiple fields
- Update multiple records using a single query for performance
- update multiple MySQL rows at once
- Updating Multiple MySQL Rows at Once
- Updating multiple records in mysql
- Most efficient way to update multiple values in Mysql using PDO
- Update multiple rows or record in database
- updating multiple rows in php/mysql