
Reputation: 119
TRPO/PPO importance sampling term in loss function
In the Trust-Region Policy Optimisation (TRPO) algorithm (and subsequently in PPO also), I do not understand the motivation behind replacing the log probability term from standard policy gradients
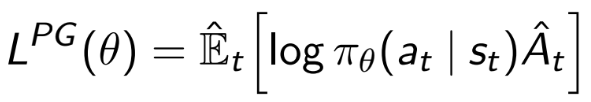
with the importance sampling term of the policy output probability over the old policy output probability
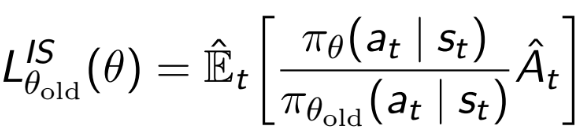
Could someone please explain this step to me?
I understand once we have done this why we then need to constrain the updates within a 'trust region' (to avoid the πθold increasing the gradient updates outwith the bounds in which the approximations of the gradient direction are accurate), I'm just not sure of the reasons behind including this term in the first place.
Upvotes: 1
Views: 936
Answers (2)

Reputation: 5412
The original formulation of PG does not have the log, it is just E[pi*A]. The log is used for numerical stability, since it does not change the optimum.
The importance sampling term must be used because you are maximizing pi (the new policy) but you have only samples from the current policy pi_old. So basically what IS does it
- You want to solve
integral pi*A - You don't have samples from
pibut only frompi_old - You change the problem to
integral pi/pi_old*pi_old*A - This is equivalent to
integral pi/pi_old*Aapproximated with samples frompi_old.
This is also useful is you want to store samples collected during previous iterations and still use them to update your policy.
However, this naive importance sampling is usually unstable, especially if your current policy is much different from the previous one. In PPO and TRPO it works well because the policy update is constrained (with KL divergence in TRPO and by clipping the IS ratio in PPO).
This is a nice book chapter for understanding importance sampling.
Upvotes: 3

Reputation: 7608
TRPO and PPO keep optimizing the policy without sampling again.
That means that the data that is used to estimate the gradient has been sampled with a different policy (pi_old). In order to correct for the difference between the sampling policy and the policy that is being optimize, an importance sampling ratio needs to be applied.
Upvotes: 1
Related Questions
- Stochastic state transitions in MDP: How does Q-learning estimate that?
- Best Reinforcement Learner Optimizer
- Does PPO's gradient clipping really prevent r(θ) from exceeding 1±epsilon?
- Objective function in proximal policy optimization
- What are the similarities between A3C and PPO in reinforcement learning policy gradient methods?
- Could anyone explain clearly how to compute the advantage function in reinforcement learning?
- What is the Full Meaning of the Discount Factor γ (gamma) in Reinforcement Learning?
- Choose function for On-Policy prediction with approximation
- Why do we need MDP setting in reinforcement learning
- How to Learn the Reward Function in a Markov Decision Process