
Reputation: 541
Leaving DEBUG logging levels in production code
In the past, my client would call to tell me that a problem occurred in their software. I would log in to the site, and look at the error logs.
However, I found that error logs tend to explain WHAT error occurred but not WHY the error occurred. An understanding of what led to the issue requires previous state information, which is only contained in DEBUG logs.
So almost every time, I would have to change the log level, restart the software, and spend a lot of time trying to recreate the issue.
I decided to leave the production code running in DEBUG log level, but with one adjustment:
I capped the max journal size using journald.conf to 10GB. On a 500GB machine this seemed fine to me.
Now I can use journalctl --since and journalctl --until to filter the huge log to the time period when my client said the error occurred.
And now I don't waste time re-creating the issue when problems come up.
My question:
What are the implications of leaving production code running on a client's site in a verbose DEBUG level?
I found the answer here inadequate: Log levels in Production
Upvotes: 3
Views: 8845
Answers (2)

Reputation: 9007
As Matthew points out the big problems are performance and noise. So what to do?
Log debug only when needed
There are three main approaches to logging DEBUG logs in production. One of my favorite patterns for this is letting your code always keep track of the debug logs, but not actually log them until an error occurs. This is called Event Driven Debug Logs and it works something like this:
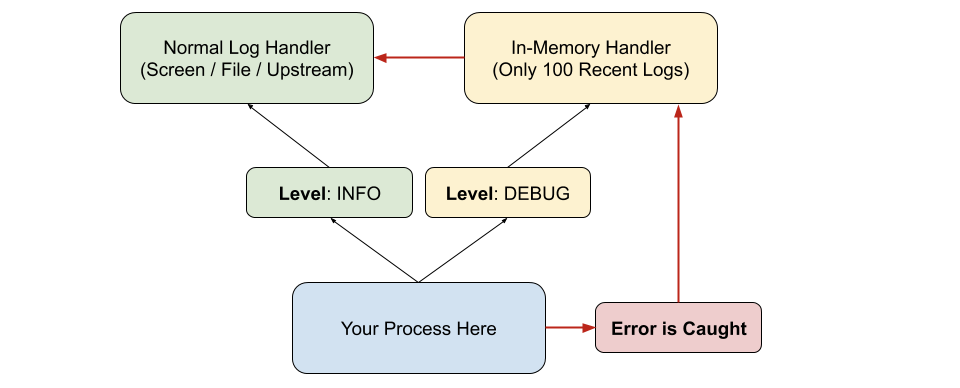
Without going into language specific implementation the idea here is that your keep In-Memory N-recent DEBUG logs and dump them to your logger only when necessary. What this "necessary" may be is up to you. Uncaught Exception? Another log at "ERROR" level? This is up to your scenario.
Upvotes: 10

Reputation: 25773
The two main issues with always logging every log message are:
Performance
Logging is not free in terms of I/O, memory, or CPU. This is apparent on both the system writing the logs, and the system(s) collecting and querying.
Noise
If 99.9% of your log lines contains information irrelevant to a problem, then when an actual problem occurs, it may be difficult to find it.
Potential Solution
Have request level logging, I have seen systems that will record debug level logs in memory for a specific request, and will only persist them to disk if an application error happens on the given request.
This might not be easy to implement on your given system, and will still incur some penalty of processing all these logs and maintaining them in memory, but it could be a good option to solve your particular problem.
Alternatively, update your existing logs to contain more contextual information. For example, the default .NET Core logging framework allows you to add contextual information along the call chain:
using (logger.BeginScope("UserId: {0}", 123))
{
// will log this message with contextual information UserId: 123
logger.LogInformation("Password does not match");
}
Thirdly, if you're able to get your system in a state where the problem is reproducible and restarting your application loses that ability, then you can update your logging framework to be able to dynamically set the minimum severity of log messages at runtime.
Upvotes: 2
Related Questions
- Changing nLog logging level in Production
- Preferred Log Level in Production
- log level in development and production asp.net core 2.2
- How to change glog log level at runtime, not compile time?
- Is it possible to change the log level for an application at compile time?
- Switch on/off logging (e.g. zlog) following dev-mode being DEBUG or RELEASE
- Is it ok to have entity framework logging set to debug window in production source code?
- Should I use log_level :debug in production on my Rails app
- Log levels: Would you consider DEBUG finer than TRACE?
- Best practices for logging on top of logging levels