Reputation: 87
Convert JSON file to Pandas dataframe
I would like to convert a JSON to Pandas dataframe.
My JSON looks like: like:
{
"country1":{
"AdUnit1":{
"floor_price1":{
"feature1":1111,
"feature2":1112
},
"floor_price2":{
"feature1":1121
}
},
"AdUnit2":{
"floor_price1":{
"feature1":1211
},
"floor_price2":{
"feature1":1221
}
}
},
"country2":{
"AdUnit1":{
"floor_price1":{
"feature1":2111,
"feature2":2112
}
}
}
}
I read the file from GCP using this code:
project = Context.default().project_id
sample_bucket_name = 'my_bucket'
sample_bucket_path = 'gs://' + sample_bucket_name
print('Object: ' + sample_bucket_path + '/json_output.json')
sample_bucket = storage.Bucket(sample_bucket_name)
sample_bucket.create()
sample_bucket.exists()
sample_object = sample_bucket.object('json_output.json')
list(sample_bucket.objects())
json = sample_object.read_stream()
My goal to get Pandas dataframe which looks like:

I tried using json_normalize, but didn't succeed.
Upvotes: 5
Views: 7446
Answers (4)

Reputation: 8084
You can try this approach:
from google.cloud import storage
import pandas as pd
storage_client = storage.Client()
bucket = storage_client.get_bucket('test-mvladoi')
blob = bucket.blob('file')
read_output = blob.download_as_string()
data = json.loads(read_output)
data_norm = json_normalize(data, max_level=5)
df = pd.DataFrame(columns=['col1', 'col2', 'col3', 'col4', 'col5'])
i = 0
for col in b.columns:
a,c,d,e = col.split('.')
df.loc[i] = [a,c,d,e,b[col][0]]
i = i + 1
print(df)
Upvotes: 1

Reputation: 2569
Not the best way, but it's work. Also you should modify flatten function that is only picked from this awnser
test = {
"country1":{
"AdUnit1":{
"floor_price1":{
"feature1":1111,
"feature2":1112
},
"floor_price2":{
"feature1":1121
}
},
"AdUnit2":{
"floor_price1":{
"feature1":1211
},
"floor_price2":{
"feature1":1221
}
}
},
"country2":{
"AdUnit1":{
"floor_price1":{
"feature1":2111,
"feature2":2112
}
}
}
}
from collections import defaultdict
import pandas as pd
import collections
def flatten(d, parent_key='', sep='_'):
items = []
for k, v in d.items():
new_key = parent_key + sep + k if parent_key else k
if isinstance(v, collections.MutableMapping):
items.extend(flatten(v, new_key, sep=sep).items())
else:
items.append((new_key, v))
return dict(items)
results = defaultdict(list)
colnames = ["col1", "col2", "col3", "col4", "col5", "col6"]
for key, value in flatten(test).items():
elements = key.split("_")
elements.append(value)
for colname, element in zip(colnames, elements):
results[colname].append(element)
df = pd.DataFrame(results)
print(df)
Upvotes: 0

Reputation: 1256
You could use this:
def flatten_dict(d):
""" Returns list of lists from given dictionary """
l = []
for k, v in sorted(d.items()):
if isinstance(v, dict):
flatten_v = flatten_dict(v)
for my_l in reversed(flatten_v):
my_l.insert(0, k)
l.extend(flatten_v)
elif isinstance(v, list):
for l_val in v:
l.append([k, l_val])
else:
l.append([k, v])
return l
This function receives a dictionary (including nesting where values could also be lists) and flattens it to a list of lists.
Then, you can simply:
df = pd.DataFrame(flatten_dict(my_dict))
Where my_dict is your JSON object.
Taking your example, what you get when you run print(df) is:
0 1 2 3 4
0 country1 AdUnit1 floor_price1 feature1 1111
1 country1 AdUnit1 floor_price1 feature2 1112
2 country1 AdUnit1 floor_price2 feature1 1121
3 country1 AdUnit2 floor_price1 feature1 1211
4 country1 AdUnit2 floor_price2 feature1 1221
5 country2 AdUnit1 floor_price1 feature1 2111
6 country2 AdUnit1 floor_price1 feature2 2112
And when you create the dataframe, you can name your columns and index
Upvotes: 1

Reputation: 336
Nested JSONs are always quite tricky to handle correctly.
A few months ago, I figured out a way to provide an "universal answer" using the beautifully written flatten_json_iterative_solution from here: which unpacks iteratively each level of a given json.
Then one can simply transform it to a Pandas.Series then Pandas.DataFrame like so:
df = pd.Series(flatten_json_iterative_solution(dict(json_))).to_frame().reset_index()
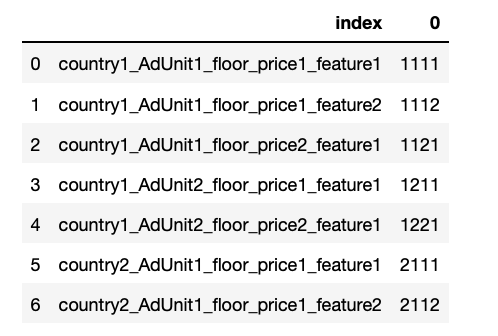{kind=link}
Some data transformation can easily be performed to split the index in the columns names you asked for:
df[["index", "col1", "col2", "col3", "col4"]] = df['index'].apply(lambda x: pd.Series(x.split('_')))
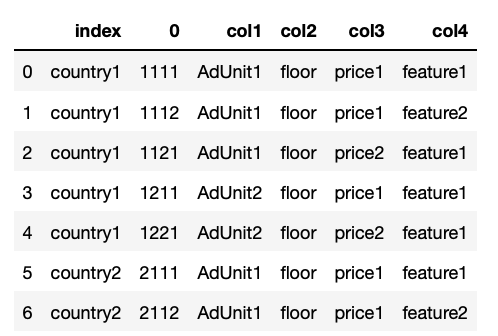{kind=link}
Upvotes: 5
Related Questions
- Python - How to convert JSON File to Dataframe
- Json file to pandas data frame
- Converting JSON file to Pandas dataframe
- convert json file to data frame in python
- Pandas DataFrame to JSON format file
- convert json into pandas dataframe
- JSON file to Pandas df
- Convert json to pandas DataFrame
- Converting JSON to a Pandas DataFrame
- Convert Json data to Python DataFrame