
Reputation: 551
Pivoting table, while preserving all columns not involved
This code will generate a very simple dummy dataframe, where people filled a survey form:
df2 = pd.DataFrame({
'name':['John','John','John','Rachel','Rachel','Rachel'],
'gender':['Male','Male','Male','Female','Female','Female'],
'age':[40,40,40,39,39,39],
'SurveyQuestion':['Married?','HasKids?','Smokes?','Married?','HasKids?','Smokes?'],
'answers':['Yes','Yes','No','Yes','No','No']
})
The output looks like so:

Because of the way the table is structured, with each question having its own row, we see that the first 3 columns always contain the same info, as it's just repeating the info based on the person that filled in the survey.
It would be better to visualize the dataframe as a pivot-table, similar to the following:
df2.pivot(index='name',columns='SurveyQuestion',values='answers')
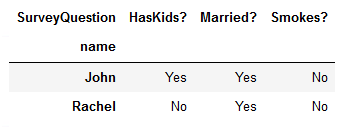
However, doing it this way results in many of the previous columns being lost, since only 1 column can be used as the index.
I'm wondering what the most straightforward way of doing this would be that didn't involve an extra step of rejoining the columns.
Upvotes: 1
Views: 50
Answers (2)
Reputation: 34086
You can use df.pivot_table:
In [27]: df2.pivot_table(values='answers', index=['name','gender','age'], columns='SurveyQuestion', aggfunc='first')
Out[27]:
SurveyQuestion HasKids? Married? Smokes?
name gender age
John Male 40 Yes Yes No
Rachel Female 39 No Yes No
OR, you can use df.pivot with df.set_index, like this:
In [30]: df = df2.set_index(['name', 'gender', 'age'])
In [32]: df.pivot(index=df.index, columns='SurveyQuestion')['answers']
Out[32]:
SurveyQuestion HasKids? Married? Smokes?
name gender age
John Male 40 Yes Yes No
Rachel Female 39 No Yes No
Upvotes: 1

Reputation: 19
I'm not sure there's any existing algorithms to do this for you but I've had a similar problem in my projects.
If you're trying to condense the rows in your table, first you need to make sure every person can have the same columns applied to them. For example, you can't reasonably do this if you didn't ask the 'HasKids?' question to Rachel unless you include an N/a option.
After this, order the table by some unique ID, that way any repeated people will definitely be next to each other in the table.
Then iterate through this table, and everytime you hit a row that's the same as the last, take whatever unique information it has, add it to the original row for that person and delete this repeat. If this is done for the whole table you should get your pivot.
Upvotes: 1
Related Questions
- How can I "unpivot" specific columns from a pandas DataFrame?
- How to pivot a pandas table just for some columns
- Pivoting column while retaining all other columns
- Pivoting data without column
- Pivot Pandas keeping only certain columns
- Transpose/Pivot DataFrame but not all columns in the same row
- Python Pandas: how to only pivot certain columns while keeping others?
- Pandas Pivot and Un Pivoting a table
- Pivot columns while retaining original column headers
- Python Pandas: pivot only certain columns in the DataFrame while keeping others