
Reputation: 582
Trouble with getting correct tag for 256-bit AES GCM encryption in Node.js
I need to write the reverse (encryption) of the following decryption function:
const crypto = require('crypto');
let AESDecrypt = (data, key) => {
const decoded = Buffer.from(data, 'binary');
const nonce = decoded.slice(0, 16);
const ciphertext = decoded.slice(16, decoded.length - 16);
const tag = decoded.slice(decoded.length - 16);
let decipher = crypto.createDecipheriv('aes-256-gcm', key, nonce);
decipher.setAuthTag(tag)
decipher.setAutoPadding(false);
try {
let plaintext = decipher.update(ciphertext, 'binary', 'binary');
plaintext += decipher.final('binary');
return Buffer.from(plaintext, 'binary');
} catch (ex) {
console.log('AES Decrypt Failed. Exception: ', ex);
throw ex;
}
}
This above function allows me to properly decrypt encrypted buffers following the spec:
| Nonce/IV (First 16 bytes) | Ciphertext | Authentication Tag (Last 16 bytes) |
The reason why AESDecrypt is written the way it (auth tag as the last 16 bytes) is because that is how the default standard library implementations of AES encrypts data in both Java and Go. I need to be able to bidirectionally decrypt/encrypt between Go, Java, and Node.js. The crypto library based encryption in Node.js does not put the auth tag anywhere, and it is left to the developer how they want to store it to pass to setAuthTag() during decryption. In the above code, I am baking the tag directly into the final encrypted buffer.
So the AES Encryption function I wrote needed to meet the above circumstances (without having to modify AESDecrypt since it is working properly) and I have the following code which is not working for me:
let AESEncrypt = (data, key) => {
const nonce = 'BfVsfgErXsbfiA00'; // Do not copy paste this line in production code (https://crypto.stackexchange.com/questions/26790/how-bad-it-is-using-the-same-iv-twice-with-aes-gcm)
const encoded = Buffer.from(data, 'binary');
const cipher = crypto.createCipheriv('aes-256-gcm', key, nonce);
try {
let encrypted = nonce;
encrypted += cipher.update(encoded, 'binary', 'binary')
encrypted += cipher.final('binary');
const tag = cipher.getAuthTag();
encrypted += tag;
return Buffer.from(encrypted, 'binary');
} catch (ex) {
console.log('AES Encrypt Failed. Exception: ', ex);
throw ex;
}
}
I am aware hardcoding the nonce is insecure. I have it this way to make it easier to compare properly encrypted files with my broken implementation using a binary file diff program like vbindiff
The more I looked at this in different ways, the more confounding this problem has become for me.
I am actually quite used to implementing 256-bit AES GCM based encryption/decryption, and have properly working implementations in Go and Java. Furthermore, because of certain circumstances, I had a working implementation of AES decryption in Node.js months ago.
I know this to be true because I can decrypt in Node.js, files that I encrypted in Java and Go. I put up a quick repository that contains the source code implementations of a Go server written just for this purpose and the broken Node.js code.
For easy access for people that understand Node.js, but not Go, I put up the following Go server web interface for encrypting and decrypting using the above algorithm hosted at https://go-aes.voiceit.io/. You can confirm my Node.js decrypt function works just fine by encrypting a file of your choice at https://go-aes.voiceit.io/, and decrypting the file using decrypt.js (Please look at the README for more information on how to run this if you need to confirm this works properly.)
Furthermore, I know this issue is specifically with the following lines of AESEncrypt:
const tag = cipher.getAuthTag();
encrypted += tag;
Running vbindiff against the same file encrypted in Go and Node.js, The files started showing differences only in the last 16 bytes (where the auth tag get's written). In other words, the nonce and the encrypted payload is identical in Go and Node.js.
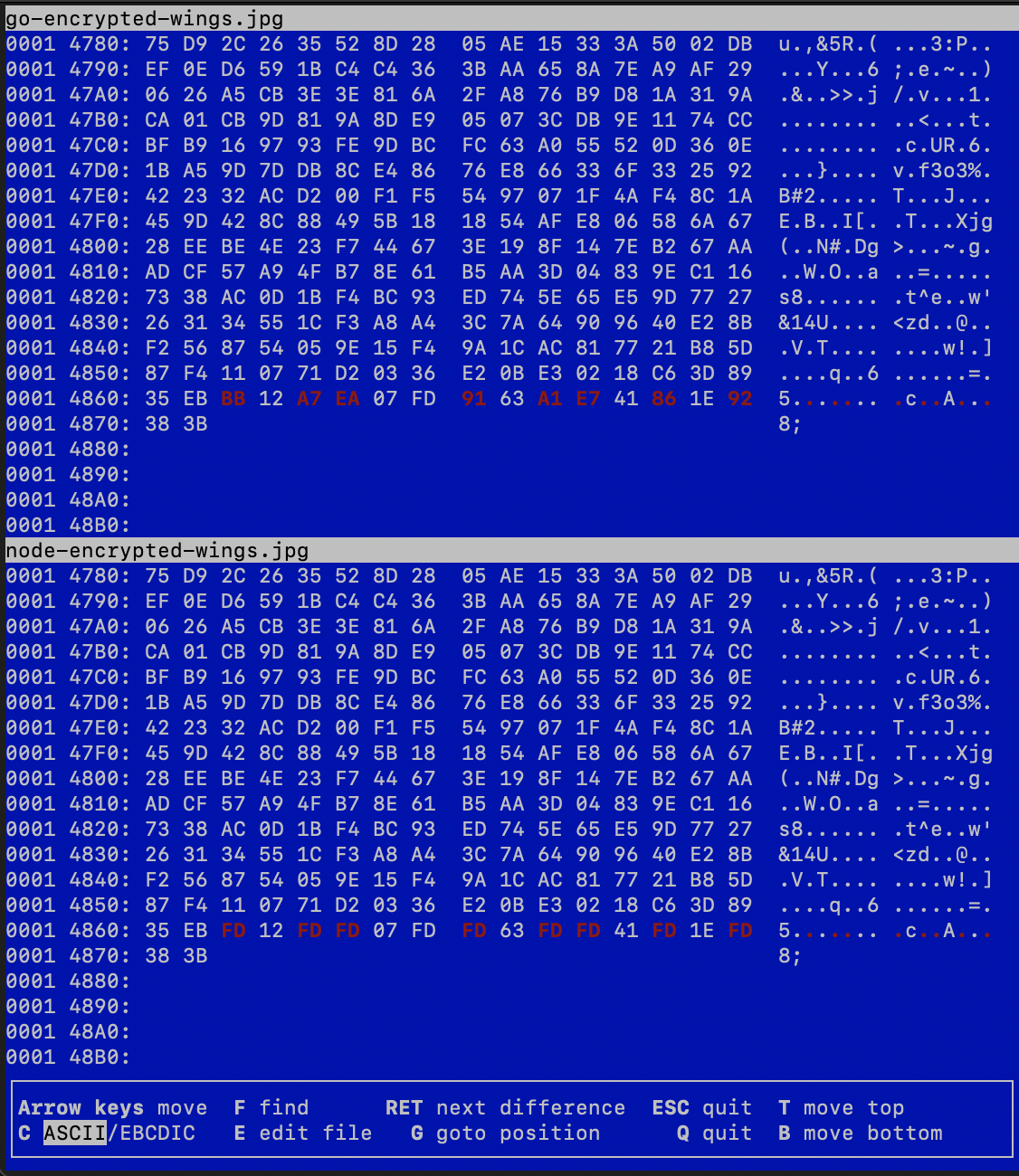
Since the getAuthTag() is so simple, and I believe I am using it correctly, I have no idea what I could even change at this point. Hence, I have also considered the remote possibility that this is a bug in the standard library. However, I figured I'd try Stackoverflow first before posting an Github Issue as its most likely something I'm doing wrong.
I have a slightly more expanded description of the code, and proof of how I know what is working works, in the repo I set up to try to get help o solve this problem.
Thank you in advance.
Further info: Node: v14.15.4 Go: go version go1.15.6 darwin/amd64
Upvotes: 3
Views: 3366
Answers (1)

Reputation: 49251
In the NodeJS code, the ciphertext is generated as a binary string, i.e. using the binary/latin1 or ISO-8859-1 encoding. ISO-8859-1 is a single byte charset which uniquely assigns each value between 0x00 and 0xFF to a specific character, and therefore allows the conversion of arbitrary binary data into a string without corruption, see also here.
In contrast, the authentication tag is not returned as a binary string by cipher.getAuthTag(), but as a buffer.
When concatenating both parts with:
encrypted += tag;
the buffer is converted into a string implicitly using buf.toString(), which applies UTF-8 encoding by default.
Unlike ISO-8859-1, UTF-8 is a multi byte charset that defines specific byte sequences between 1 and 4 bytes in length that are assigned to characters, s. UTF-8 table. In arbitrary binary data (such as the authentication tag) there are generally byte sequences that are not defined for UTF-8 and therefore invalid. Invalid bytes are represented by the Unicode replacement character with the code point U+FFFD during conversion (see also the comment by @dave_thompson_085). This corrupts the data because the original values are lost. Thus UTF-8 encoding is not suitable for converting arbitrary binary data into a string.
During the subsequent conversion into a buffer with the single byte charset binary/latin1 with:
return Buffer.from(encrypted, 'binary');
only the last byte (0xFD) of the replacement character is taken into account.
The bytes marked in the screenshot (0xBB, 0xA7, 0xEA etc.) are all invalid UTF-8 byte sequences, s. UTF-8 table, and are therefore replaced by the NodeJS code with 0xFD, resulting in a corrupted tag.
To fix the bug, the tag must be converted with binary/latin1, i.e. consistent with the encoding of the ciphertext:
let AESEncrypt = (data, key) => {
const nonce = 'BfVsfgErXsbfiA00'; // Static IV for test purposes only
const encoded = Buffer.from(data, 'binary');
const cipher = crypto.createCipheriv('aes-256-gcm', key, nonce);
let encrypted = nonce;
encrypted += cipher.update(encoded, 'binary', 'binary');
encrypted += cipher.final('binary');
const tag = cipher.getAuthTag().toString('binary'); // Fix: Decode with binary/latin1!
encrypted += tag;
return Buffer.from(encrypted, 'binary');
}
Please note that in the update() call the input encoding (the 2nd 'binary' parameter) is ignored, since encoded is a buffer.
Alternatively, the buffers can be concatenated instead of the binary/latin1 converted strings:
let AESEncrypt_withBuffer = (data, key) => {
const nonce = 'BfVsfgErXsbfiA00'; // Static IV for test purposes only
const encoded = Buffer.from(data, 'binary');
const cipher = crypto.createCipheriv('aes-256-gcm', key, nonce);
return Buffer.concat([ // Fix: Concatenate buffers!
Buffer.from(nonce, 'binary'),
cipher.update(encoded),
cipher.final(),
cipher.getAuthTag()
]);
}
For the GCM mode, a nonce length of 12 bytes is recommended by NIST for performance and compatibility reasons, see here, chapter 5.2.1.1 and here. The Go code (via NewGCMWithNonceSize()) and the NodeJS code apply a nonce length of 16 bytes different from this.
Upvotes: 3
Related Questions
- AES 256 GCM encryption decryption in nodejs
- "Unsupported state or unable to authenticate data" with aes-128-gcm in Node
- AES-256-GCM Encryption from Ruby & Decryption with Golang
- AES/GCM/NoPadding encrypt from node and decrypt on java, throw AEADBadTagException: Tag mismatch
- AEAD AES-256-GCM in Node.js
- AES-256-GCM in Nodejs
- Tag mismatch error in AES-256-GCM Decryption using Java
- nodejs AES-128-GCM "invalid initialization vector length"
- Cannot decrypt AES-256 GCM with Java
- How to use id-aes256-GCM with Node.JS crypto? "TypeError: DecipherFinal fail"