
Reputation: 2420
MySQL is too smart about accented characters
I guess, normally people would be aiming to make their programme behave like this, but in my case this is completely opposite from what I want.
Somehow, my MySQL database is able to read different accented characters as identical. For instance, shī, shí, shǐ, shì and shi are all the same thing to it. When I search for one, I’ll get the others as well. Proofpic:
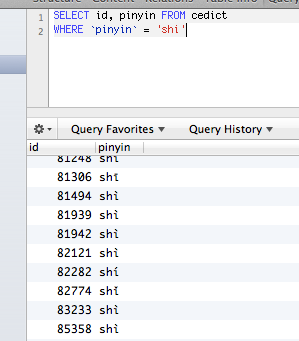
This is not what I want, since for me those values are very different. Basically, the query on the pic must return empty rows, because there is no a single entry in that table with shi (without an accent).
My tables type is InnoDB, collation is utf8_general_ci.
Upvotes: 4
Views: 313
Answers (1)

Reputation: 62395
Use utf8_bin collation. You don't have to change collation of entire column, you can just use it on per query basis
WHERE `pinyin` = 'shi' COLLATE utf8_bin
You can also experiment with different collations which might work better for you (utf8_bin works on binery level, so even if two unicode characters with different byte codes are the same, it will see them as different).
Upvotes: 2
Related Questions
- php screws up utf-8 characters from mysql database using mysqli
- MySQL cannot recognize Korean characters
- How to setup MySQL to handle unicode diacriticals properly?
- Accented characters in mySQL table
- MySQL returns incorrect UTF8 extended characters in some cases only
- MySQL Chinese pinyin encoding issue
- mySQL database chinese characters get represented as?
- Unicode character issue with Chinese Characters
- MySQL not storing foreign characters correctly
- database not storing accented characters properly