
Reputation: 9447
Recommended database type to handle billion of records
I started to work in a project which must reuse a Microsoft SQL Server 2008 old database that has a table with more than 7,000,000 records.
Queries to that table last minutes and I was wondering if a different type of database (i.e. not relational) would be better to handle this.
What do you recommend? In any case, is there a way to improve the performance of a relational database?
Thanks
UPDATE:
I am using Navicat to perform this simple query:
SELECT DISTINCT [NROCAJA]
FROM [CAJASE]
so complex stuff and subqueries are not a problem. I was also wondering if a lack of indexes was the problem, but the table seems to be indexed:
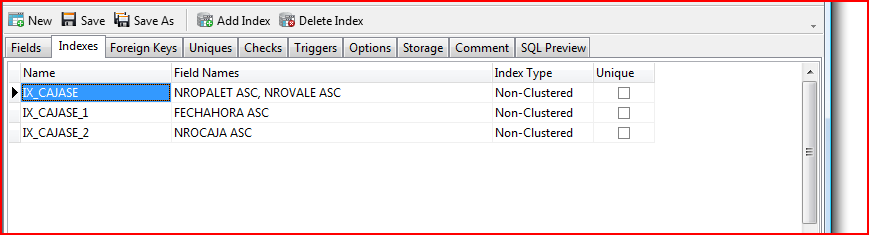
EPIC FAIL:
The database was in a remote server!! The query actually takes 5 seconds (I still think it's much time, but now the issue is different). 99% of elapsed time was network transfer. Thanks for your answers anyway :)
Upvotes: 0
Views: 477
Answers (3)

Reputation: 1
The fact that you are selecting "distinct" could be a problem. Maybe move those distinct value into it's own table to avoid duplication.
Upvotes: 0

Reputation: 96650
7 million is a tiny database for SQL Server, it easily handles terrabytes of data with proper design. Likely you have a poor design combined with missing indexes combined with poor hardware, combined with badly performing queries. Don't blame the incompetence of your database developers on SQL Server.
Upvotes: 3

Reputation: 52699
Profile your queries - 7 million records isn't that great a number, so chances are you're missing an index or performing complex sub-queries that are not performing well as the dataset scales.
I don't think you need to re-architect the entire system yet.
Upvotes: 2
Related Questions
- Recommendations for database structure with huge dataset
- Can I keep 100 million records in single table or multiple table?
- Best database solution for managing a huge amount of data
- Handling large databases
- What is the best database design for thousand rows
- Which DB used for the application that deals with milions of the rows
- SQL Database design for huge datasets
- Best way to store large dataset in SQL Server?
- 30 million records a day, SQL Server can't keep up, other kind of database system needed?
- Database design--billions of records in one table?