
Reputation: 7666
Autocorrect spelling mistakes in text input
I am writing a natural language processor in C# that extracts the sentiment (positive/negative) of a sentence. There is something of an issue, though, in being able to discern the sentiment of a misspelled word - if it's not in the dictionary, I can neither tag it nor rate it!
I know there has to be a way to handle this. Google gives accurate suggestions all the time, I simply need to take the top suggestion from a similar algorithm and hit the database with it. The problem is, I'm not sure where to start with algorithm names and so forth. I need help figuring that out.
I checked around on the site for similar questions, and found some concepts that seemed useful, but the basic way of handling the distance between a misspelling and a real word basically relied on hitting every word in your data set, which seems horribly inefficient. Some help with ideas to make the algorithm run quickly would also be much appreciated; this analysis engine is supposed to be able to handle multiple thousands of items a day.
Thanks in advance.
Upvotes: 4
Views: 2829
Answers (3)

Reputation: 11494
The prefix trees mentioned by @dierre are extremely useful if you want to efficiently calculate the edit distance between a misspelling and a large set of dictionary words. Brill and Moore (2000) describe an approach using prefix trees using the same general approach as Norvig and many other spell checkers. Their paper is available here: http://www.ldc.upenn.edu/acl/P/P00/P00-1037.pdf
Upvotes: 1

Reputation: 300
The approach given by dierre - including Peter Norvig's Article - is certainly worth being considered further.
However, for a quick-and-dirty solution: if a possibly misspelled word is not found in your own dictionary, you can try to find a mapping in this list of common misspellings
Upvotes: 2

Reputation: 7220
This problem is not that stupid. Norvig wrote an article about it. Generally speaking the difficulty depends on the accuracy. The "easiest" way to do it is using a prefix tree or trie to avoid exploring all possibilities. Basically you have something like this:
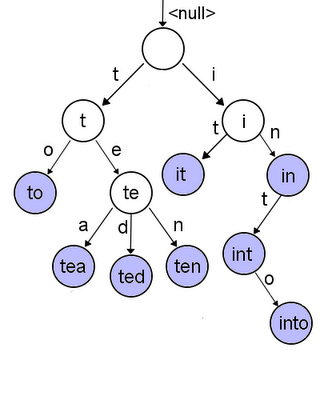
and following the path you basically stay on track. Once you reach a point where you are stuck you should check how to move on based on the type of error you have.
You can read Norvig's article for a deeper analysis.
Upvotes: 4
Related Questions
- Algorithm in .NET to detect simple typos
- How to detect a "typo" for a certain phrase or regex?
- Intelligent spell checking
- Spell check in winforms
- NetSpell spellchecker
- Spelling checker for .NET
- AutoCorrect Text C# Word
- C# Win Form Spell Checker .Net 3.5
- SpellCheck in c#
- Suggestive Spelling Checker based on edit distance and lcs?