
Reputation: 6720
How to generically create a thumbnail corresponding to a given RSS feed's article
So I'm brainstorming right now and would like to hear your thoughts on this.
So you know the news app, pulse?
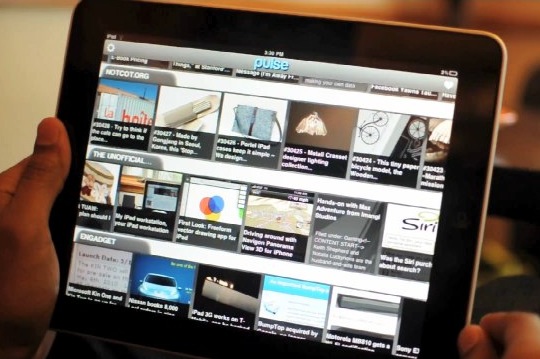
As you can see it pulls thumbnails from virtually any news source.
I'm curious as to how they gather the title and image from various sources since their RSS feeds will always vary.
I was thinking, for each article in the RSS feed, I would just iterate over its content until I find a preg_match for an image source.
Is that the best way to generically determine the image? ..How about the title?
:)
Upvotes: 0
Views: 128
Answers (1)

Reputation: 848
The titles is obviously from the RSS. Look at any rss feeds for their title tags.
Probably the only tricky part is the thumbnail. However some RSS feeds like Engadget http://www.engadget.com/rss.xml; has image associate with each article (under the CDATA of the description tag) which can be easily regex match.
Upvotes: 1
Related Questions
- Supply an image thumbnail with my RSS feed
- How to add a thumbnail for wordpress in an rss feed
- Getting media:thumbnail from XML
- How do you add thumbnail images to RSS feed?
- Wordpress cropped thumbnail for RSS feed
- Grab images with php from an rss feed
- Add thumbnail to WordPress RSS with another tag
- Would like to add image / thumbnail for items in my Perl generated RSS feed
- PHP - Grab image url from RSS feed
- Rss Feed, generating the image