
Reputation: 79185
Oracle hierarchical query on non-hierarchical data
I hava data in an Oracle table that is organized as a graph that can contain cycles (see example).
CREATE TABLE T (parent INTEGER, child INTEGER)
AS select 1 parent, 2 child from dual
union all select 1 parent, 8 child from dual
union all select 2 parent, 3 child from dual
union all select 2 parent, 4 child from dual
union all select 2 parent, 8 child from dual
union all select 3 parent, 4 child from dual
union all select 3 parent, 6 child from dual
union all select 4 parent, 5 child from dual
union all select 5 parent, 8 child from dual
union all select 6 parent, 5 child from dual
union all select 7 parent, 3 child from dual
union all select 7 parent, 5 child from dual
union all select 8 parent, 6 child from dual
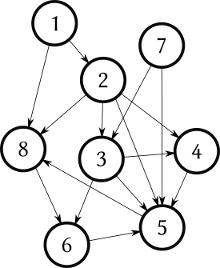
My goal is to get all nodes that are descendants (children, children of children, etc.) of node X. Let's say 2. My expected result is then: 3, 4, 5, 6, 8.
I know that I can design a query like this:
SELECT child, sys_connect_by_path(child,'/')
FROM T
START WITH parent = 2
CONNECT BY NOCYCLE PRIOR child = PARENT;
The problem with such a query is that it will go through all possible paths until they cycle, and there are way too many of them in my actual data. The result consists of many duplicates – Here it is:
child | sys_connect_by_path (for information)
3 | /3
4 | /3/4
5 | /3/4/5
8 | /3/4/5/8
6 | /3/4/5/8/6
6 | /3/6
5 | /3/6/5
8 | /3/6/5/8
4 | /4
5 | /4/5
8 | /4/5/8
6 | /4/5/8/6
8 | /8
6 | /8/6
5 | /8/6/5
My actual data is much more complex. the cost of execution of such a query is so huge that my TEMP tablespace, which was autoextendable, reached 10Gb (originally 500 Mb) and my database actually broke because of disk full.
I tried to design the query like this (recursive WITH clause) :
WITH descendants(node) AS
( SELECT 2 node FROM dual
UNION ALL
(
SELECT child
FROM T
INNER JOIN descendants D
ON T.parent = D.node
MINUS SELECT node FROM descendants
)
)
SELECT * FROM descendants
The problem that I encounter is:
- with Oracle 10g, this is not implemented (
ORA-32033: unsupported column aliasing, and some customers use Oracle 9 or 10), - with Oracle 11g, I get
ORA-32041: UNION ALL operation in recursive WITH clause must have only two branches. If I remove the MINUS clause I will get cycles (ORA-32044: cycle detected while executing recursive WITH query).
How would you query my original data to get those nodes 3, 4, 5, 6, 8 efficiently? PL/SQL solutions are also welcome.
Thank you.
Upvotes: 14
Views: 3116
Answers (3)

Reputation: 11
This might help until visited exceeds 4000 bytes. Cycles should not be possible but the line is there just as an example.
WITH descendants(node, lvl, pth, visited) AS
(
SELECT child node, 1, cast(child as varchar2(4000)), '/'||listagg(child,'/') within group (order by child) over()||'/'
FROM t
where parent = 2
UNION ALL
SELECT child, lvl+1, pth||'/'||child, D.visited||listagg(child,'/') within group (order by child) over()||'/'
FROM T
INNER JOIN descendants D
ON T.parent = D.node
WHERE D.visited not like '%/'||child||'/%'
)
cycle node set cyc to '1' default '0'
SELECT distinct node
FROM descendants
order by node
;
Upvotes: 1

Reputation: 8069
I have not worked with this myself, but what about a CONNECT BY with the NOCYCLE option? That should stop travering the tree when it sees a loop. Oracle 11i definitely has that, I think it came in somewhere in the Oracle 10g period.
Upvotes: 1

Reputation: 86715
What is your expected maximum depth to reach any child node?
If it's relatively small, you could loop down, while checking for nodes you have already visited, in a manner something like this...
(Note, I'm not an Oracle expert so this is closer to pseudo code with a little real SQL mixed in)
CREATE TABLE myMap (parent INT, child INT);
INSERT INTO myTable SELECT NULL, 2 FROM DUAL;
WHILE (SQL%ROWCOUNT > 0)
LOOP
INSERT INTO
myMap
SELECT DISTINCT
dataMap.parent,
dataMap.child
FROM
myMap
INNER JOIN
dataMap
ON myMap.child = dataMap.parent
WHERE
NOT EXISTS (SELECT * FROM myMap WHERE parent = dataMap.parent)
END LOOP;
Depending on performance, you may also want a depth field in myMap; optimising the join so as to only join on the most recent nodes. This would imply two indexes; one for the JOIN (depth) and one for the NOT EXISTS (parent).
EDIT
Added the DISTINCT key word, to avoid the following case...
- Node 2 maps to 3 and 4
- Nodes 3 and 4 both map to node 5
- All children of node 5 would now be processed twice
GROUP BY, or many other options, can be used to cater for this instead of DISTINCT. It's just that the NOT EXISTS on it's own is not sufficient.
Upvotes: 2