
Reputation: 11
Encoding Issue When Attempting to Convert Hindi Script PDF to CSV in Python
I'm currently attempting to convert a PDF file containing Hindi Devanagari script to a CSV file using the fitz library in Python, but when I read in the text I encounter a strange encoding issue.
Here is a page from the PDF:
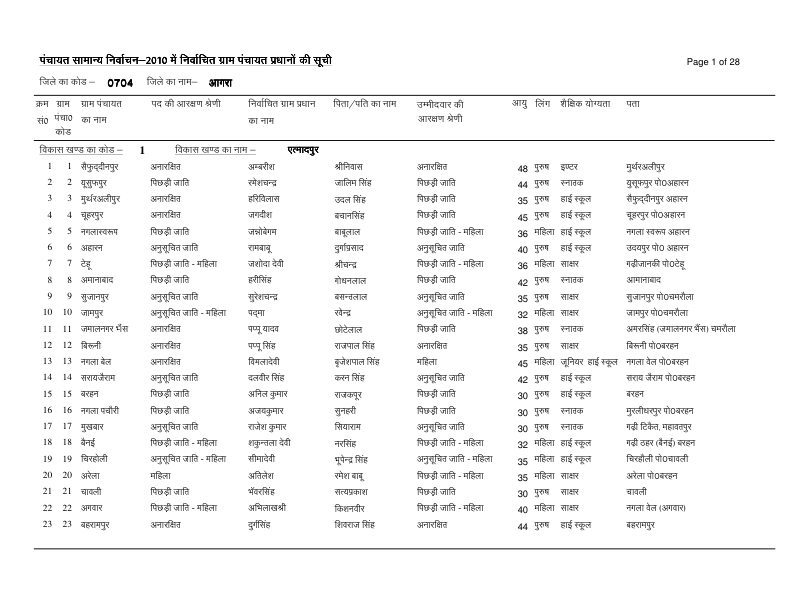{kind=link}
I am using the following code to read in the text:
import fitz
from indic_transliteration import sanscript
from indic_transliteration.sanscript import transliterate
def extract_text_from_pdf(pdf_file):
text = ""
with fitz.open(pdf_file) as pdf_document:
for page_num in range(len(pdf_document)):
page = pdf_document.load_page(page_num)
text += page.get_text()
return text
def devanagari_to_roman(text):
return transliterate(text, sanscript.DEVANAGARI, sanscript.ITRANS)
def main():
pdf_file = 'data/agra_2010.pdf'
extracted_text = extract_text_from_pdf(pdf_file)
roman_text = devanagari_to_roman(extracted_text)
print(roman_text)
if __name__ == "__main__":
main()
But here is an example of how the Hindi text appears in the output:
òû£û™û
òû£û™û
òû£û™û
òû£û™û
ftys dk uke&
ftys dk dksM &
I encounter the same issue when using the tabula function read_pdf, so this isn't simply an issue with the library I'm using. I would like to maintain the Hindi script in my output. Please let me know if you have any solutions. Thanks!
Upvotes: 1
Views: 275
Answers (1)

Reputation: 11725
You did not supply that corrupt file, but it is not hard to find a very similar corruption on the web.

That is an everyday problem, a non-standard font has been used so the numbers on the surface do not match the ink. I have selected the "fuok" part. And we see the Devanagari ink is top left stored as a f. 2nd row down & 3rd from left is the binary u and its Devanagari ink appearance etc.
The good news is that the Latin fonts are correctly embedded. Also this should be one of the easier to fix types, since it seems there are few or no repeats.
Bad news is that is a darn slow manual haul, to verify two full alphabets of mapping, and you may still finish with rubbish.
Let's start with the keycode for f  = "U+093F: DEVANAGARI VOWEL SIGN I"
= "U+093F: DEVANAGARI VOWEL SIGN I" ि so we need to re-map that key then VA NA (I probably have those wrong ?).
Certainly some will look better but when replacing characters in that fashion they usually end up worse.
So forget editing inside PDF by simple find and replace unless you want to retype the lot. Due to the BiDi overlay, all the letter positions will be corrupted without additional kerning. Forgive my lack of correctly matching a character or two here (on the plain text at right) we see the Hindi characters will not be overlaid as expected.

It is simpler to use the plain text by find and replace using a similar but binary numerically programmable means using Devanagari inside a word processor.
So import into MS Word and use find and replace Hindi style it will be better. Thus, a VBA programming solution is required.

Upvotes: 0
Related Questions
- Cannot display HTML string
- PyPDF returning Junk encodes
- Importing rotated text from a PDF table such as with tabula-py in python
- Skip errors and continue loop when url provides no file
- Setting the correct encoding when piping stdout in Python
- Tabula-py skips first page from PDF and misses some tabular data
- Problem in calling Python script from PHP