
Reputation: 6916
Any gain on performance when using single vs multiple databases?
We are building a software that receives pre-calculated hour averages of about 100 data items per system that are sent about once per day. There might be about 20 customers with 5-50 systems. So the theoretical maximum will roughly 100 * 24 * 20 * 50 = 2400000 rows inserted per day.
It is very unlikely that there will be that many inserts per day, but that is something that we need to keep in mind.
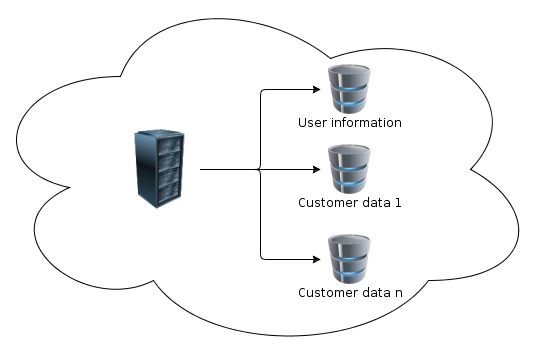
Is there performance gain if we split database structure so that each customer will have it's own database like in the last picture? In the shared database there would be users and their associations to the databases.
Or
Update
Data will kept for about 2-3 years and then system will automatically delete old data. Users are not deleting "anything", in this context anything means data that is sent from the customer systems.
Update 2
In the images there is a cloud around server and database. To be more specific: that cloud is Microsoft Azure implementation of cloud computing.
Upvotes: 4
Views: 1709
Answers (4)

Reputation: 29639
I see your question largely as one related to "multi tenancy" design - how do you design a single system for use by several users? it's common in "software as a service" products like Basecamp etc.
I'm not aware of any definitive answers, but my usual recommendation is similar to socha23: design your solution so it can support multiple databases, but only go that way if you need to.
In general, having a single solution for every user is MUCH easier to manage. You only have to back up one database. You only have to deploy a single codebase. Your configuration files are easy to keep in sync.
Having separate infrastructure (hardware or software) for individual customers immediately makes everything a lot more complex - and you should invest in heavy automation to manage that complexity (I recommend the "continuous delivery" approach - http://continuousdelivery.com/). The cost goes well beyond hardware or software licenses - so you should only incur that cost if there's a good reason to do it.
This presumably is why most SaaS providers have tiered services. In your case, you might offer a "gold" customer their own database if they are prepared to pay for the additional performance.
Upvotes: 0

Reputation: 425188
A better, more general, solution is to run a master db and several slave (read-only, automatically kept in synch with master) dbs. Updates are sent to the master, but selects are distributed along all dbs (since selects will get the same result no matter where the query is run).
There are many products that do this "out of the box", both open source and commercial.
Upvotes: 0

Reputation: 26719
There would be performance gain in both reading and writing of data, if the databases are on different physical disks. If they are on the same disk/server, the performance gain will be too small to bother. On the other hand, if you use multiple servers, the important question is can you query them in parallel? If you can't, most likely you won't benefit from the performance gain as much as you could.
Having many inserts is an I/O bound operation,so you have to optimize the disk access. Splitting load on different disk is the best way you could do, but if you can't, you still can improve performance:
- Make sure writes are append-only. In MySQL/InnoDB data is stored in the order of primary key, so use auto-increment to avoid random writes. In other RDBMs you can choose your cluster key, so choose wisely
- If you can, save data on one dist and bin logs on another disk - you will effectively split the load to 2 disks this way
- If you can split reading and writing (master/slave replication), so the master would be busy only with writing
Upvotes: 0

Reputation: 10239
If each Customer works using only his own data, and doesn't need to access other customers data, I think some performance is to be gained thanks to the fact that table locks will only affect data of one customer, so for example when customer A runs a cascade delete on a table, other customers will still be able to read and modify data from the same table in their respective databases. Without such a split, table locks affect all.
That being said, splitting the database will make administration (making backups, modifying the database structure, updating database addresses etc) more troublesome and error-prone.
You could start with one database, holding all the data. Then, if you find out customers often wait till other customers operations finish, you can split the database; if you properly abstracted database access, no big changes in code should be needed.
Remember, premature optimization is the root of all evil!
Upvotes: 1
Related Questions
- Multiple databases vs a single database
- Single or multiple databases
- When to use multiple databases vs multiple tables
- SQL Server performance - schema vs multiple databases
- Will creating seperate databases in SQL Server give me better performance?
- Application design single vs multiple databases
- Multiple databases vs single db
- Single or multiple databases
- What would be better, (1 database + 4 tables) or (2 databases + 2 tables each)?
- What are the pros/cons of and best practices for using a single database?