
Reputation: 7029
Vexing regex pattern
I have some malformed json strings that I am trying to fix. To accomplish that I was planning on splitting the string up into tokens, fixing each token when necessary and then recombine the tokens into a valid json string. Steps two and three are working great, it is the first step, tokenizing the string, that is causing me problems.
Here is an (highly edited) example of one of these strings:
userId: "someUserId"
application: "some Application"
request: {
strategy: 1
locations: [
{
locationId: "1"
}
{
locationId: "2"
}
]
}
I would like to tokenize it so that I have an array like this:
userId:
"someUserId"
application:
"some Application"
request:
{
strategy:
1
locations:
[
{
locationId:
"1"
}
{
locationId:
"2"
}
]
}
I can get really close using this simple regex pattern \s+ like this:
$tokens = $json -split '\s+'
The only problem with that is that is splits strings with spaces so "some Application" becomes:
"some
Application"
I have struggled for a while now to turn that simple pattern into something magical that will do exactly what I want but so far that has only yielded results that are, frankly, too embarrassing to post.
Upvotes: 1
Views: 90
Answers (3)
Reputation: 7029
So far the other answers are not giving the results that I am looking for so I am going to throw my own answer in the ring. This appears to do exactly what I want:
$tokens = $json -split '(?<=[\[\]{}:"]|[\[\]{}:][^"]+)\s+'
I will leave this question open for a bit until I am sure I did not miss some edge case.
Upvotes: 0

Reputation: 4578
So you wish to tokenize the sample string, capturing word:, "word", numbers, and parenthesis and brackets.
([\w"]+\s?[\w]*:?)|([{}\[\]])
will capture those groups, including "word words". Here is a demo.
Breakdown. First group will get the words, with an optional space, and zero or more words following, with an optional :.
Second group will capture all of the brackets and parentheses.
Using a findall or gm should get you all matches.
Upvotes: 0

Reputation: 47832
I was able to get this working with the following:
(?m)(?:^|(?<=[:\{\[]))[\r\s]+
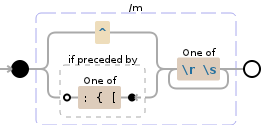
But I'm not certain it will work in every case you might come across (it works on your sample data).
Breakdown
(?m) puts it in multiline mode which lets ^ and $ match the beginning and end of each line (as opposed the whole string).
Then I'm alternating between the beginning of a line (^) or a lookbehind for the characters :, {, or [, before finally matching the one or more whitespace.
To explain further:
(?:) this is the same as just using parentheses, except it's a non-capturing group. It's just a slight efficiency boost; you don't need to capture the contents, we only want it for alternation with |.
(?<=) this is a lookbehind, a zero-width match (whatever it matches won't be included as part of the match, but it must be true to proceed).
[:\{\[] this is just a character class, matching a single character that must be one of the ones specified. \{ is used to represent a literal {, same with \[ (they're escaped).
The lookbehind is used so that the preceding character exists but isn't part of the match (otherwise it would be consumed in the split).
Based on your comment, I changed \s+ to [\r\s]+ to match carriage returns.
Upvotes: 2
Related Questions
- PowerShell regex script
- Advanced pattern matching in Powershell
- Regular Expressions on powershell
- Regular expression matching in PowerShell
- Regular Expressions - Powershell
- Regex patterns in Powershell
- Powershell Regular Expression
- powerShell and regular expression
- Powershell regexp
- powershell regular expressions