
Reputation: 10539
Binary search with looking nearby values
I am trying to find, if someone implemented binary search in following way -
Let suppose we have array of some elements, placed in contiguous memory.
Then when you compare middle element, the next few elements should be already in the the CPU cache. Comparing should be already free?
Yet I can not find anyone who doing this.
If no one do that, what could be the reason?
Upvotes: 3
Views: 241
Answers (2)

Reputation: 2973
Classic binary search can be thought of as defining a binary tree structure on the elements. For example, if your array has 15 elements numbered 1 through 15, you would start out by looking at the middle element "8", and from there go either left or right to element "4" or "12":

(from Brodal et al, "Cache oblivious search trees via binary trees of small height", SODA'02, PDF preprint link)
What you are proposing is essentially adding a few more elements into each node, so that the "8" element would also contain some adjacent elements e.g. "9", "10", "11". I don't think this has been studied extensively before, but there is another very related idea that has been studied, namely going from a binary tree (with two children on each node) to a B-ary tree ("B-tree", with B children on each node). This is where you have multiple elements in a node that split up the resulting data into many different ranges.
By comparing a search key to the B-1 different elements in a node, you can determine which of the B children to recurse into.
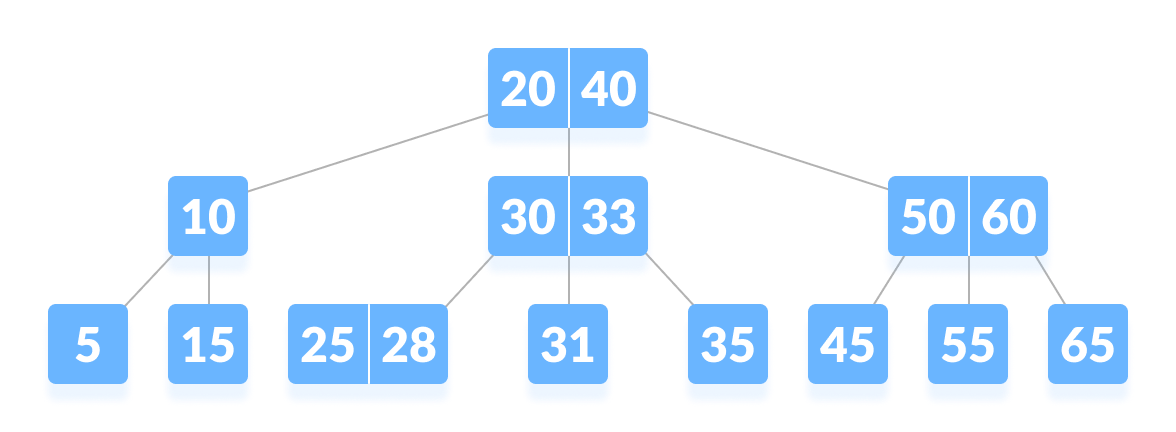
It's possible to rearrange the elements in an array so that this search structure can be realized without using pointers and multiple memory allocations, so that it becomes just as space-efficient as doing binary search in a regular sorted array, but with fewer "jumps" when doing the search. In a regular sorted array, binary search does roughly log_2(N) jumps, whereas search in a B-tree does only log_2(N) / log_2(B) = log_B(N) jumps, which is a factor log_2(B) fewer!
Sergey Slotin has written a blog post with a complete example of how to implement a static B-tree that is stored implicitly in an array: https://algorithmica.org/en/b-tree
Upvotes: 3

Reputation: 5424
I think your proposal is decent, although it is slightly more complicated than you might think at first. It will only work for situations where the data under comparison is in the contiguous array itself (rather than having the array hold pointers). This is less common in higher-level languages.
From there it gets more technical. Are you going to go for L1 cache or L2 cache? Actually, it's probably only "free" if it's in the L1 cache. Are you going to query the CPU architecture to get the cache line sizes or are you going to use specs from a common architecture? Does your OS and architecture allow you to determine your spot in the cache line based on the address modulus? (I assume that it can be determined, but I don't know that for sure.)
You're trying to go faster than O(log(n)). How many jumps can you save with this approach? If your next jump is in the same cache line, you've done more work by iterating. It only helps when your target is in your cache line but your next jump is not. The L1 cache line might contain 8 (8-byte) or maybe 16 (4-byte) values, only half of which are usable if we land in the middle of the cache line on average.
I think at this point it becomes data-dependent. Can you predict that your target is "close" to your current spot? And by close, I mean within 16 values? To be that close means you're within log2(16)=4 close jumps, and the odds are that some of those jumps are in the cache. All of them are probably in the L2 cache. After all this, I think it's not worth it; you won't be any faster.
Upvotes: 2
Related Questions
- At what point does binary search become more efficient than sequential search?
- Practical Efficiency of binary search
- Binary search code fails efficiency check
- Small sized binary searches on CUDA GPUs
- Modifying Binary Search to obtain better performances
- Beating binary search using CPU cache line
- Why is this implemented binary search so much slower than std::binary_search()?
- Effective search in specific intervals
- Optimized binary search
- Fast binary search/indexing in c